Why Transformer Performance Is Mostly a Matmul Problem
In brief
In brief
Most Transformer compute is expressed as matrix multiplication, but delivered performance depends on tensor shapes and data movement. Large prefill matrices can use tensor cores efficiently, while decode often becomes narrow and memory-bound.
- Peak FLOPs matter only when matrix shapes and tiling keep GPU compute units occupied.
- Kernel performance depends on reusing data across HBM, shared memory, registers, and tensor cores.
- Prefill and decode require different optimization strategies because their matrix shapes differ.
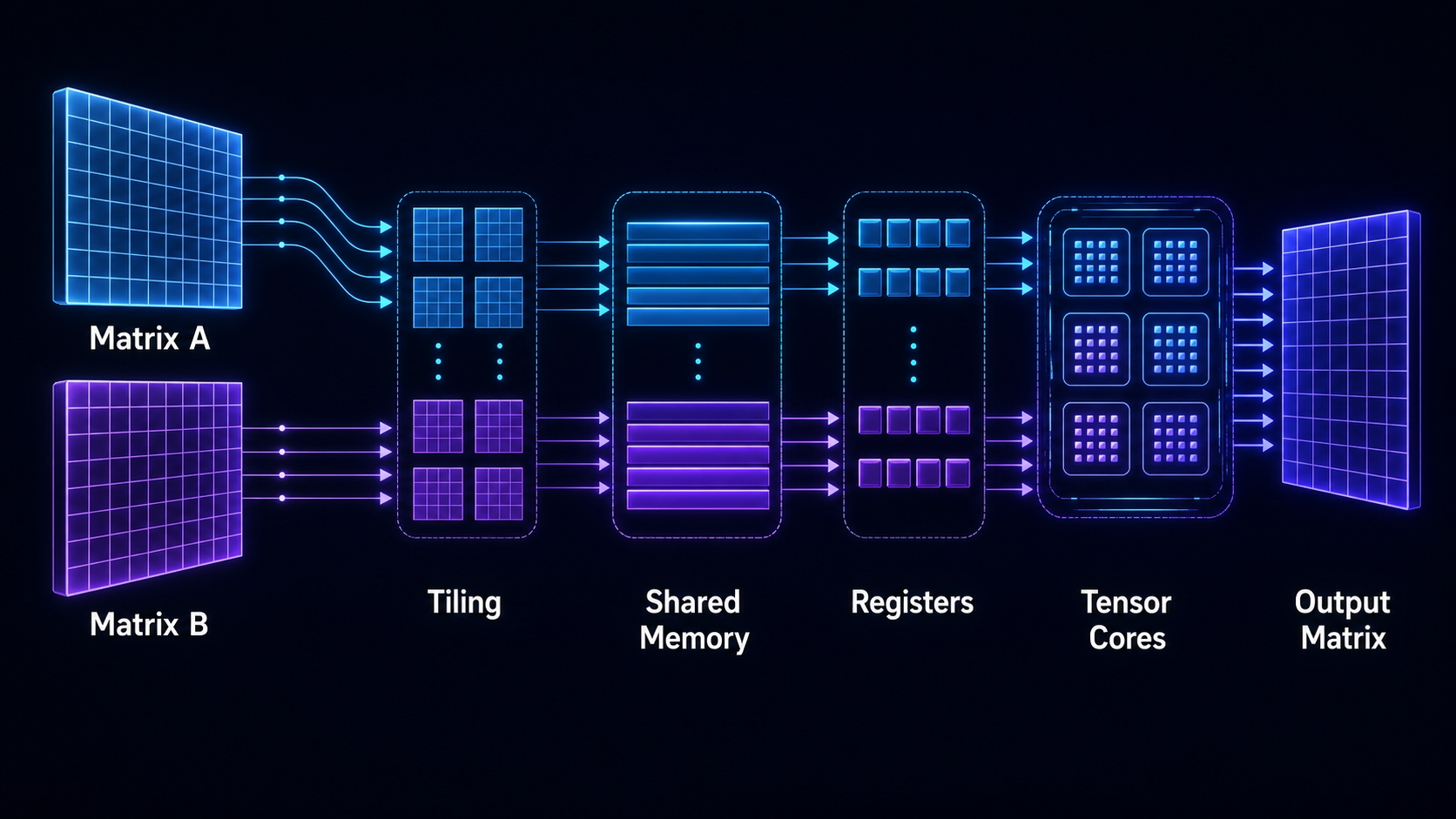
How Transformer computation maps onto GPU matrix multiplication kernels.
The same Transformer equation can produce very different performance depending on the shape that reaches the GPU. A prefill batch with thousands of prompt tokens gives the kernel a large, regular matrix. A decode step with a small active batch can be skinny, memory-sensitive, and much harder to keep efficient.
That is why Transformer performance keeps returning to matrix multiplication. Query, key, and value projections are matmuls. MLP projections are matmuls. The vocabulary projection is a matmul. Once the model defines those shapes, performance depends on how the GPU moves tiles through memory, feeds tensor cores, and overlaps data movement with computation.
The Transformer view tells us what computation is required. The kernel view tells us whether the hardware can run that computation efficiently. A line like Q = XWq hides how data is loaded from memory, how work is split across thread blocks and warps, how tiles are reused, how tensor cores are fed, and how partial results are accumulated.
Matrix multiplication is not the only operation in inference, and attention kernels have their own specialized structure. The diagnostic reason to focus here is that dense Transformers spend a large share of their FLOPs in matmuls, especially in linear projections and MLPs.
The phrase "mostly a matmul problem" should not be read as "only matmul matters." Layer normalization, elementwise activations, attention score computation, softmax, sampling, communication, and memory allocation all matter. The narrower claim is diagnostic: if theoretical FLOPs do not become real token throughput, the data path around matmul is one of the first places to inspect.
1. Transformer Computation Becomes Matrix Multiplication
Start with the equations from the previous post:
Here X is the input hidden state for a batch of tokens, and the W matrices are learned projections. The model uses these projections to produce attention queries, keys, and values.
The MLP is also built from linear projections:
Depending on notation, the matrices may appear on the left or right, but the core operation is the same: multiply an activation matrix by a weight matrix, optionally apply an elementwise operation, then multiply again.
The final vocabulary projection is another matmul:
For a large vocabulary, this can be a meaningful cost, especially when the batch of active decode tokens is small.
In rough form, the Transformer is a stack of routing operations and feature transformations. The expensive feature transformations mostly reduce to matrix multiplications.
The shapes come from both the model and the request. If the active tokens in a batch form an activation matrix with shape M x K, and a projection weight has shape K x N, the output has shape M x N. In prefill, M can be large because prompt tokens are processed together. In decode, M may be closer to the number of active requests, because each request often contributes one new token. The same weight matrix can see very different activation shapes depending on the phase.
In kernel terms, the core projection is:
This shape change is one reason inference is hard to summarize with a single benchmark. A large prefill matmul may have enough work to keep tensor cores busy. A small decode matmul may have less parallelism and may spend more relative time on memory movement, kernel launch overhead, or cache reads. The model equation is the same. The hardware problem is not.
Weights are reused across tokens, while activations are request-specific. A server running one model keeps the same weight matrices resident, but each batch brings new activations, new sequence lengths, and new cache reads. Kernel efficiency depends on how much reuse the current shape allows.
This is the prefill/decode split in hardware terms. During prefill, a prompt with thousands of tokens can create an activation matrix with many rows. During decode, the active matrix may have one row per running request. A skinny matmul can be mathematically correct and still be a poor match for the hardware.
2. GPUs Are Built Around Massive Parallelism
Matrix multiplication is a good fit for GPUs when it exposes enough independent arithmetic. Each output element is a dot product. A large output matrix contains many dot products, and those dot products can be split across many parallel workers.
An NVIDIA GPU is organized around streaming multiprocessors, or SMs. Each SM executes groups of threads called warps. The programmer describes a kernel as thread blocks; the GPU schedules those blocks across SMs. Data-center GPUs also include tensor cores, specialized units designed to accelerate matrix multiply-accumulate operations for data types such as fp16, bf16, fp8, and related tensor formats.
At a high level, a GPU does two jobs:
- Move and store data.
- Do arithmetic on that data.
The second job is what appears in model equations. The first job is where performance explanations often live.
3. Memory Hierarchy Often Decides the Bottleneck
Fast GPU programming is often about putting data in the right place at the right time. Which level dominates depends on the operation, shape, precision, kernel, and accelerator; the hierarchy is a diagnostic lens, not a universal verdict.
Global memory has large capacity but relatively high latency. L2 cache is closer. L1 and shared memory are closer still. Registers are closest to the executing threads. Tensor cores can perform enormous amounts of arithmetic, but they cannot multiply data that has not arrived.
Naive matmul can be slow because every output element repeatedly reads the same input values from global memory. The arithmetic is simple; without reuse, data movement becomes the limiting failure.
Counting operations is not enough. The diagnostic question is how many operations the kernel gets per byte moved. This is the intuition behind arithmetic intensity and the Roofline model: attainable performance is bounded by peak compute at high arithmetic intensity and by memory bandwidth at low arithmetic intensity. A computation with high reuse can do many multiply-accumulate operations after loading a tile. A computation with poor reuse may spend most of its time waiting for data. The boundary is hardware- and kernel-specific, not a universal label attached to an operator.
The same FLOP count can behave differently across shapes. A matmul with generous dimensions can reuse tiles well. A thin or irregular matmul may expose memory and scheduling overhead. Attention during decode can be especially sensitive because it repeatedly reads KV cache for active sequences. The bottleneck is not always the part that looks largest in a clean equation.
Weight-only quantization is another example of the compute/memory tradeoff. Smaller weights can reduce bandwidth pressure and improve cache residency, but the benefit depends on kernels that can use the compressed format efficiently. If dequantization overhead or unsupported shapes dominate, the expected speedup may not appear. The model-level idea is simple: use fewer bits. The kernel-level result depends on the path those bits take.
High-performance matmul is less about individual multiply-adds than about moving data through the memory hierarchy efficiently.
Reuse is the reason to stage data. If a tile of matrix A and a tile of matrix B are loaded from global memory, the kernel wants to spend that load across many multiply-accumulate operations before discarding the tile. The closer that reuse happens to the compute units, the better.
4. Tiling Is the Central Idea
Tiling is the main way a kernel turns a huge matmul into reusable local work instead of repeated global-memory traffic.
Suppose we want:
C = A x BInstead of computing each element independently from global memory, the kernel divides A, B, and C into tiles. A block of threads loads a tile of A and a tile of B into shared memory. Threads then multiply smaller fragments and accumulate partial results in registers. The kernel advances along the reduction dimension, loading the next tiles and accumulating until the output tile is complete.
A small example makes the reuse visible. Imagine one tile of A and one tile of B are loaded from global memory. If those values are used once, the load was expensive. If the same tile values contribute to many output elements before being evicted, the load becomes worthwhile. Shared memory and registers are more than faster storage; they are places where reuse is made explicit.
The picture is:

Tiling looks like an implementation detail, but it changes the diagnosis. It is the reason the same value loaded from memory can contribute to many arithmetic operations. Without that reuse, the kernel can be memory-bound even when the model equation looks compute-heavy.
There are several tile levels: thread-block tiles, warp tiles, instruction-level fragments, and tensor-core fragments. Choosing these sizes is a tradeoff among occupancy, register pressure, shared-memory capacity, memory coalescing, and the shape of the matrices.
Those tradeoffs are real. Larger tiles can improve reuse, but they consume more shared memory and registers. More register use can reduce occupancy or cause spilling. Better occupancy can hide latency, but only if the kernel still feeds tensor cores efficiently. Strong kernels are tuned around hardware limits and workload shape, not around a single "larger is better" rule.
For LLM inference, matrix shapes vary by phase. Prefill may involve larger sequence dimensions. Decode may involve small batches of new tokens, where weight loading and KV-cache reads become more visible. The same model equations can stress kernels differently depending on request mix.
A useful back-of-the-envelope performance model compares arithmetic work to data movement:
Arithmetic intensity makes the same point as a ratio:

5. Tensor Cores Change the Unit of Computation
Tensor cores are specialized matrix engines. Instead of thinking only in scalar multiply-add instructions, high-performance kernels feed tensor cores small matrix fragments. Hopper-class NVIDIA GPUs such as H100 are one concrete example: NVIDIA documents fourth-generation Tensor Cores, FP8 support, Tensor Memory Accelerator, and asynchronous execution features. Those details explain a current NVIDIA path; they should not be read as a portable description of every GPU.
For NVIDIA GPUs, the programming stack has multiple layers. CUDA is the familiar high-level interface. PTX is a lower-level virtual instruction set. SASS is the machine-level instruction form produced for a specific architecture. You do not need to write SASS to understand LLM inference, but the distinction explains why high-performance kernels are architecture-aware. The same mathematical matmul can map to different instruction sequences depending on GPU generation and compiler behavior.
Tensor cores are a capability, not an automatic outcome. The kernel has to present data in a layout and precision the hardware can use. The batch shape has to provide enough independent work. Memory movement has to keep pace. If any of those fail, the operation may use only a fraction of advertised throughput.
Tensor cores can deliver a large fraction of their peak throughput only when the kernel gives them the right work: supported datatypes, compatible layouts, staged fragments, and enough independent matrix work to hide latency.
6. Asynchronous Pipelines Hide Latency
If a kernel loads data, waits, computes, stores, and repeats, it leaves performance on the table. Better kernels overlap these steps.
On architectures with the right support, high-end matmul kernels can move tiles while tensor cores compute on previous tiles. A common pattern is producer-consumer scheduling: some work prepares data movement into shared memory, while other work consumes ready tiles through tensor core operations. On Hopper, TMA is one documented mechanism for moving large data blocks between global memory and shared memory; other GPU generations expose different mechanisms and constraints. Buffers form a small pipeline. As one tile is being used, another tile is being loaded.
Strong kernels hide memory latency by overlapping data movement with tensor core execution. If loading, staging, computing, and storing happen as separate blocking phases, expensive compute units sit idle. If the kernel keeps the next tiles in flight while tensor cores consume the current tiles, latency is absorbed into running work.
This pipeline is delicate. Shared-memory layout can create bank conflicts. Register use can become too high and cause spilling. Tile shapes can underuse tensor cores. Memory access patterns can fail to coalesce. Hardware power and clock behavior can also affect sustained throughput.
The model equation hides this pipeline; delivered throughput depends on it.
Three implications follow. First, theoretical FLOPs are not delivered token throughput; tensor cores only help when kernels feed them efficiently. Second, inference has shape problems: online traffic mixes prefill and decode, long and short prompts, changing batch sizes, and changing active-request counts. Third, kernel performance depends on serving decisions. Chunked prefill, continuous batching, and paged attention all change the shapes and memory paths that kernels actually see.
The kernel view does not replace the model view or the serving view. It explains the hardware consequences of both.
Diagram: Matmul Through the GPU Memory Hierarchy
The arrows should be read as a data path, not a strict one-time sequence. High-performance kernels pipeline this movement so load, compute, and store overlap.
A Performance Lens for Transformer Operations
When a Transformer operation is slow, the first questions should be concrete:
Is the operation large enough to use the GPU well?
Small decode batches may underuse compute because there is not enough parallel work. Large prefill batches may use compute better but consume more memory and delay other requests.
Is the bottleneck arithmetic or memory movement?
MLP matmuls can be compute-heavy. Attention during decode may spend much of its time reading KV cache. The final vocabulary projection can become significant with small batches and large vocabularies.
Are data layouts and precision aligned with hardware?
Tensor cores are optimized for particular fragment shapes and data types. A model using bf16, fp16, fp8, or quantized weights will depend on kernels that exploit those formats correctly.
Does the serving layer produce efficient shapes?
The scheduler can help or hurt. It decides how much work enters a kernel call and how prefill and decode are interleaved.
Here the kernel view meets the serving view. A scheduler that forms larger batches may improve kernel utilization, but larger batches can increase waiting time. Chunked prefill can make long prompts less disruptive, but it also changes the sequence of kernel shapes. Continuous batching can keep decode work flowing, but the active batch may still be too small or too irregular for ideal tensor-core use.
A matmul kernel does not know that one row came from a short chat request and another came from a long document summary. It sees shapes, pointers, layouts, and datatypes. The serving engine is the layer that turns irregular user traffic into those shapes.
GPU utilization has to be read against the workload target. High utilization may come from large prefill work that delays streaming tokens. Low utilization may be acceptable for sparse low-latency traffic. The question is whether the system is using the hardware well for the promised TTFT, inter-token latency, throughput, and tail behavior.
The same kernel can look excellent or mediocre depending on the batch it receives, and that batch is made by the serving layer.
Key Takeaways
- Dense Transformer arithmetic is dominated by matmuls in projections, MLPs, and often the vocabulary head.
- Delivered throughput depends on data movement, tile reuse, and tensor-core-friendly shapes.
- Shared memory, registers, and asynchronous pipelines make expensive loads reusable.
- Prefill and decode create different kernel shapes, so the same equation can hit different bottlenecks.
- Serving policy can make strong kernels look better or worse by changing the batches they receive.
Series Navigation
-
Series index: The Life of a Token Across the LLM Stack
-
Part 2: Why Transformer Performance Is Mostly a Matmul Problem (current)
Citation
Please cite this article as:
Ji, Wenbo. “Why Transformer Performance Is Mostly a Matmul Problem”. fusheng-ji.github.io (June 2026). https://fusheng-ji.github.io/blog/posts/transformer-performance-matmul-gpu/
Or use the BibTeX entry:
@article{ji2026transformerperformancematmulgpu,
title = {Why Transformer Performance Is Mostly a Matmul Problem},
author = {Ji, Wenbo},
journal = {fusheng-ji.github.io},
year = {2026},
month = {June},
url = {https://fusheng-ji.github.io/blog/posts/transformer-performance-matmul-gpu/}
}References
- Aleksa Gordic, Inside NVIDIA GPUs: Anatomy of high performance matmul kernels.
- Aleksa Gordic, Inside the Transformer: The Life of a Token.
- Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.
- Dao, FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.
- Williams, Waterman, and Patterson, Roofline: An Insightful Visual Performance Model for Multicore Architectures.
- NVIDIA, NVIDIA Hopper Architecture In-Depth.
- NVIDIA, CUTLASS Documentation.
- NVIDIA, CUDA C++ Programming Guide.
- NVIDIA, Parallel Thread Execution ISA.
Note: This blog was drafted and polished with assistance from ChatGPT, based on my reading notes on Aleksa Gordic's Transformer, matmul, and vLLM articles. Illustrations were generated with GPT Image 2.