The Life of a Request Inside vLLM
In brief
In brief
A vLLM-style engine converts independent text requests into continuously changing batches constrained by token budgets and KV-cache capacity. The scheduler balances prefill throughput, decode latency, memory ownership, and token streaming.
- Continuous batching rebuilds execution batches as requests arrive, advance, and finish.
- Paged KV cache decouples logical token sequences from contiguous physical memory.
- Throughput and interactive latency depend on scheduler policy as much as model speed.
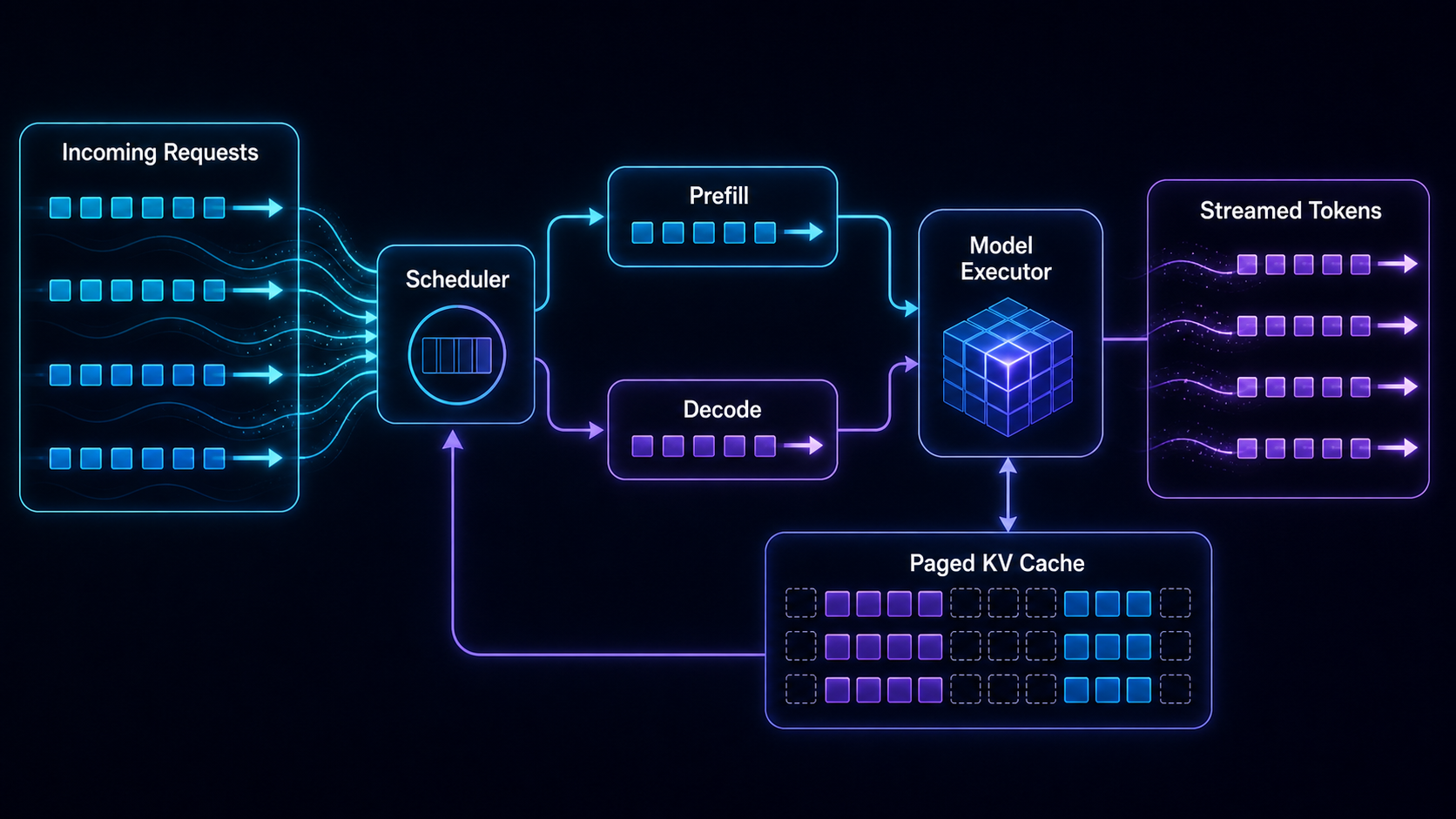
How high-throughput serving systems turn Transformer execution into an online service.
A model answers one mathematical question: given input tensors and weights, what are the next-token logits? An inference engine has to answer a more operational question every few milliseconds: which requests run next, how should they be batched, and where should their KV cache live?
A Transformer forward pass is not yet an inference service.
It is the expensive computation at the center of the service, but it is still only one part of the service. A real service has to accept requests, tokenize prompts, schedule prefill and decode, allocate KV-cache blocks, run model execution, sample tokens, stream outputs, handle completion, and keep the GPU busy while other requests are doing the same thing.
Systems such as vLLM fill this gap by making request state and cache state explicit. The engine is doing more than calling the model. It is deciding which tensors should be computed next, which requests should wait, and where the memory for each live sequence should sit.
High-throughput LLM serving is not the same as making one request fast. The engine has to keep the GPU busy while irregular requests compete for compute, KV-cache memory, and scheduler slots. That is where good kernels can still produce bad product latency.
1. From Model Execution to Inference Engine
The engine state has three pieces worth separating:
- The request state: prompt tokens, generated tokens, sampling parameters, status, and output stream.
- The model executor: the component that actually runs model computation on one or more GPUs.
- The scheduler and memory manager: the logic that chooses which requests run and where their KV cache lives.
A vLLM-style engine is easiest to understand as a repeated serving loop. The scheduler selects work. The KV cache manager allocates cache blocks. The model executor runs the chosen batch. Sampling turns logits into token IDs. Finished tokens are returned to the caller, and unfinished requests re-enter the loop.
This loop repeats until each request finishes.
The unit of control is no longer "run this prompt to completion." It is "run the next schedulable step for the current set of active requests."
The engine is managing state, not simply calls. A waiting request may have text and sampling parameters but no cache yet. A running request may own cache blocks and be waiting for its next decode step. A request in prefill may have only part of its prompt processed if chunked prefill is enabled. A finished request still needs cleanup: output delivery, stop-condition handling, and cache release.
That statefulness is the difference between a library call and a serving system. The model executor computes. The engine decides when computation happens, which requests share it, and how memory state survives between iterations.
2. Prefill and Decode Are Different Workloads
Every autoregressive request has two phases, and they create different pressure on the system.
Prefill processes the prompt. If the prompt has 2,000 tokens, the model needs to build hidden states and KV cache for those 2,000 positions. This phase has more parallelism because prompt tokens can be processed together.
Decode generates new tokens. At each step, the model usually processes one new token per active request while attending back to cached keys and values. This phase repeats many times and reads from KV cache at every step.
Prefill is often compute-heavy. Decode is often memory/KV-cache dominated. The balance changes with model architecture, batch shape, context length, quantization, attention implementation, and hardware, so these are workload descriptions rather than phase labels with fixed bottlenecks.
This distinction shapes serving behavior. A long prefill can delay other requests before they see a first token. Decode steps are individually smaller, but a request may need hundreds or thousands of them. The serving engine has to interleave these phases without starving either side of the workload.
Two user-facing latency metrics separate the setup phase from the repeated decode loop:
Chunked prefill helps by splitting long prompt processing into smaller units. Instead of letting one huge prompt monopolize scheduling, the engine can process part of it, then allow decode work from other requests to continue. This improves responsiveness, especially time-to-first-token and tail latency under mixed workloads.
Chunking is not free. Smaller chunks can improve fairness and reduce decode starvation, but they may also reduce the amount of large, efficient prefill work in a single step. Larger chunks can be better for throughput, but they can block interactive decode. The right setting depends on prompt length distribution, latency target, and how much cache pressure the workload creates.
This pattern shows up repeatedly in serving: a knob that improves one metric can hurt another. Prefill/decode scheduling is not about finding a universally correct policy. It is about choosing a policy for the traffic the service actually sees.
3. Continuous Batching Helps Keep the GPU Busy
Traditional batching works when a fixed set of examples starts and finishes together. Online LLM traffic does not look like that.
Requests arrive at different times. Prompts have different lengths. Outputs finish at different lengths. Some requests are waiting for prefill, some are decoding, some have stopped, and new ones may arrive every moment.
Continuous batching treats serving as a dynamic scheduling loop. At each iteration, the engine can:
- Admit waiting requests if there is capacity.
- Continue decode steps for active requests.
- Process prefill chunks.
- Remove finished requests.
- Reclaim KV cache.
This can improve throughput because the batch can change over time. The GPU no longer has to wait for the longest request in a fixed batch before accepting new work, provided runnable work and cache capacity are available.
The cost is scheduler complexity. The engine needs policies: how much prefill to admit, how much decode to prioritize, how to respect memory limits, and how to avoid pathological tail latency.
One way to think about each scheduler iteration is:
inspect waiting and running requests
estimate token and cache budgets
choose prefill chunks and decode steps
allocate or reuse KV-cache blocks
run the model executor
sample and stream tokens
update request state
release finished cacheThe details vary by implementation, but this loop captures the control problem. The scheduler is repeatedly converting a messy set of user requests into a batch shape the model executor can run.

The word "continuous" matters because the batch is not fixed. A request can enter after another request has already started. A finished request can leave without forcing the whole batch to end. Online LLM serving differs from offline batch inference because the system is always re-forming the next unit of work.
4. KV Cache Becomes a First-Class System Object
The KV cache begins as a Transformer optimization. During autoregressive generation, previous keys and values do not change, so storing them avoids recomputation.
Inside a serving system, the cache becomes memory management. Each request needs cache space proportional to its active sequence length, number of layers, number of key/value heads, head dimension, and dtype. Long contexts multiply this cost. Concurrent requests multiply it again.
The engine has to allocate cache, address it during attention, release it when a request finishes, reuse it when prefixes match, and decide what happens when memory is full. KV cache is a memory-management problem, not a pure attention tensor.
A serving estimate starts with bytes per cached token. It depends on number of layers, number of key/value heads, head dimension, dtype, and sometimes parallelism strategy. Multiply that by sequence length and active requests, and KV cache can dominate available VRAM. That is how a model that fits in memory at load time can still fail under concurrent long-context traffic.
Across active requests, the cache footprint is approximately:
This is a capacity estimate, not an exact allocator report. It assumes ordinary cached keys and values and omits alignment, block rounding, metadata, temporary buffers, prefix sharing, cache compression, and the effects of tensor or pipeline parallelism. It is useful for explaining the scaling pressure, then a deployment should measure its actual cache manager.
The cache manager has to behave like an allocator. It needs free blocks, used blocks, mappings from request positions to physical locations, and cleanup when requests finish. It also has to cooperate with the scheduler. A request cannot be admitted if there is no cache capacity for its prompt or expected generation.
5. PagedAttention: Virtual Memory for KV Cache
PagedAttention is the paper-level idea that made vLLM known: instead of storing each request's KV cache in one contiguous allocation, divide cache into fixed-size blocks. A request's logical token sequence maps to physical cache blocks. Despite the name, the central contribution here is cache allocation and addressing; it should not be confused with changing the model's learned attention rule.
The current vLLM documentation is careful here: its Paged Attention page is a historical explanation of the original paper and no longer a literal description of all current code paths. That is fine for this article, because the concept we need is the allocator model, not a line-by-line kernel guide.
The analogy is virtual memory. A process sees a logical address space, while the operating system maps pages to physical memory frames. In vLLM, a request sees a logical token history, while the engine maps that history to KV cache blocks.
This can reduce waste. If a request grows token by token, it can receive new blocks as needed rather than reserving a large maximum context region upfront. If it finishes, its blocks can be returned to the pool. For variable request lengths, block allocation can reduce fragmentation, although block size and allocator policy still leave some internal slack.
Paged attention also gives an attention implementation a way to read non-contiguous cache through block tables or equivalent mappings. That has kernel implications, but the systems meaning is the main point: flexible cache allocation can raise effective concurrency under irregular sequence lengths.
The mapping can be read as a block table from logical token blocks to physical KV-cache blocks:
Here

The tradeoff is indirection. The system gains flexible allocation, but kernels now need block tables to find the physical cache locations for a logical sequence. That indirection has to be implemented efficiently. PagedAttention is valuable because it makes the memory problem tractable without giving up the ability to run attention over each request's logical history.
The analogy to virtual memory has limits. KV cache blocks are not operating-system pages. They are serving-system objects designed around attention kernels and GPU memory. The mapping is the part that matters: logical continuity for the request, physical flexibility for the allocator.
6. Prefix Caching and Repeated Prompts
Serving workloads often repeat prompt prefixes. A chat application may reuse the same system prompt. A coding assistant may repeatedly include repository instructions. A retrieval pipeline may share boilerplate formatting.
Prefix caching stores KV cache for shared prompt prefixes so later requests can reuse that computed state. If two requests begin with the same tokens and the relevant cache blocks are still available, the second request may not need to recompute the prefix.
This changes the cost model. A long prompt is not always equally expensive if much of it is reusable. But caching also needs policies. The engine has to identify prefixes, store cache entries, manage memory pressure, and decide what to evict. Current vLLM docs describe a hash-based approach over KV-cache blocks and note that only full blocks are cached; the general lesson is that cache reuse depends on exact prefix identity and cache lifetime.

Prefix caching only pays off when the workload has stable repetition: shared system prompts, reused templates, retrieval formats, tool schemas, or multi-turn conversations that preserve earlier context. It pays less when prompts are mostly unique or when cache pressure forces frequent eviction. The optimization saves computation, but it spends memory and bookkeeping.
The scheduler also has to account for the hit. A request with a cache hit may need less prefill work than its raw prompt length suggests. A request without a hit may still be expensive. Two prompts with the same token length can have different serving cost depending on cache reuse.
If a request has prefix length
7. Speculative Decoding
Autoregressive decoding has a stubborn sequential dependency: each token depends on previous tokens. Speculative decoding tries to reduce the cost of that dependency.
The common pattern uses a smaller draft model or draft mechanism to propose several tokens. The larger target model then verifies those tokens in fewer larger steps. If the draft is good, multiple tokens are accepted. If not, the target model corrects the path.

The benefit depends on draft quality, target-model cost, acceptance rate, and implementation overhead. It is not free speed. It is a tradeoff that can improve throughput or latency in the right regime.
From the serving perspective, speculative decoding adds more scheduling and state. The engine must coordinate draft generation, target verification, cache updates, and sampling correctness.
Speculative decoding is attractive because decode is sequential at the interface: one accepted token changes the context for the next. A draft model tries to get ahead by proposing several tokens. The target model checks them. If several are accepted, the service effectively advances multiple tokens with fewer expensive target-model iterations.
The limitation is acceptance. If the draft model often guesses poorly, the target model rejects more proposals and the extra work may not pay for itself. There is also operational complexity: another model or draft mechanism, additional cache behavior, verification logic, and more moving parts in the scheduler.
Speculative decoding is a workload-dependent tradeoff, not free faster decode.
8. Multi-GPU and Multi-Node Serving
When model weights do not fit on one GPU, the executor has to distribute computation. Tensor parallelism shards matrix operations across GPUs. Pipeline parallelism splits layers across stages. Data parallelism runs multiple replicas to serve more traffic.
vLLM abstracts much of this behind engine and executor boundaries, but the exact process layout varies by version and deployment mode. A local deployment, a multiprocess GPU deployment, and a larger data-parallel serving setup expose different operational shapes even when the model API looks similar.
The model view still matters. Large hidden sizes, layer counts, and vocabulary projections affect how sharding behaves. The kernel view still matters. Communication and computation must be arranged so GPUs do not wait unnecessarily. The serving view adds admission, routing, and load balancing.
9. Serving Is Measured Differently From Model Quality
Model quality metrics do not tell you whether an inference service works well.
A serving system is judged by:
- Time to first token.
- Inter-token latency.
- Request throughput.
- Token throughput.
- Tail latency.
- GPU utilization.
- KV-cache memory efficiency.
- Cost per generated token.
- Stability under bursty traffic.
Benchmarking has to reflect workload shape. A benchmark with short prompts and short outputs may hide long-context problems. A benchmark with only prefill may miss decode bottlenecks. A benchmark with fixed batches may overstate online-serving performance.
Auto-tuning matters because the best configuration depends on model, hardware, sequence lengths, request mix, and latency targets. Batch limits, prefill chunk sizes, parallelism settings, cache block sizes, and decoding options are all workload-sensitive.
A serving benchmark should say what it is measuring:
- prompt length distribution
- output length distribution
- request arrival pattern
- concurrency level
- time-to-first-token target
- inter-token latency target
- cache reuse assumptions
- hardware and parallelism setup
Without that context, a tokens-per-second number can be misleading. It may describe a throughput-oriented batch workload, not an interactive chat workload. Or it may describe a short-context workload that says little about long-context behavior.
The serving layer is often where product performance is decided, but it cannot override model and hardware limits. The Transformer defines the computation. The kernels define how efficiently the accelerator can execute it. The engine decides how real traffic is shaped into that computation under memory limits.
Diagram: Request Flow Inside an Inference Engine
This loop is the serving view in one picture. Requests do not enter the model once and disappear. They circulate through scheduling, execution, sampling, output, and cache management until completion.
The Full Stack Reappears
The Transformer tells us what computation is needed. Matmul kernels explain how that computation runs on GPUs. vLLM-style serving explains how that work is organized under real workloads.
The request is the serving-level counterpart to the token. A token flows through layers. A request flows through queues, cache blocks, executor calls, and streaming outputs.
Once both are visible, LLM inference stops looking like a single model call. It becomes an online system built around scarce compute, scarce memory, and irregular demand.
Serving systems turn model capability into product performance. A model may have strong quality and fast kernels, but users experience queueing, time to first token, inter-token latency, streaming behavior, and tail latency under load.
Throughput and latency are coupled here. Batching more work can improve GPU utilization, but it can also increase waiting time. Caching prefixes can reduce repeated prefill, but it consumes memory. Speculative decoding can reduce expensive target-model steps, but it adds coordination. The engine has to choose among these tradeoffs continuously.
Key Takeaways
- The model executor computes tensors; the engine decides which request state gets computed next.
- Prefill is prompt-wide setup work; decode is repeated cache-reading work.
- Continuous batching keeps work moving as requests arrive, finish, and change length.
- KV cache is a serving object that must be allocated, addressed, reused, and released.
- PagedAttention, prefix caching, and speculative decoding help specific workloads while adding scheduling state.
Series Navigation
-
Series index: The Life of a Token Across the LLM Stack
-
Part 2: Why Transformer Performance Is Mostly a Matmul Problem
Citation
Please cite this article as:
Ji, Wenbo. “The Life of a Request Inside vLLM”. fusheng-ji.github.io (June 2026). https://fusheng-ji.github.io/blog/posts/life-of-a-request-vllm/
Or use the BibTeX entry:
@article{ji2026lifeofarequestvllm,
title = {The Life of a Request Inside vLLM},
author = {Ji, Wenbo},
journal = {fusheng-ji.github.io},
year = {2026},
month = {June},
url = {https://fusheng-ji.github.io/blog/posts/life-of-a-request-vllm/}
}References
- Aleksa Gordic, Inside vLLM: Anatomy of a High-Throughput LLM Inference System.
- vLLM Project, Architecture Overview.
- vLLM Project, Paged Attention.
- vLLM Project, Automatic Prefix Caching.
- Kwon et al., Efficient Memory Management for Large Language Model Serving with PagedAttention.
- Leviathan et al., Fast Inference from Transformers via Speculative Decoding.
- Chen et al., Accelerating Large Language Model Decoding with Speculative Sampling.
- Agrawal et al., SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills.
- vLLM Project, Speculative Decoding Examples.
- NVIDIA, TensorRT-LLM Documentation.
Note: This blog was drafted and polished with assistance from ChatGPT, based on my reading notes on Aleksa Gordic's Transformer, matmul, and vLLM articles. Illustrations were generated with GPT Image 2.