From π0 to π0.7: A Tutorial on Open-pi and Robot Foundation Models
In brief
In brief
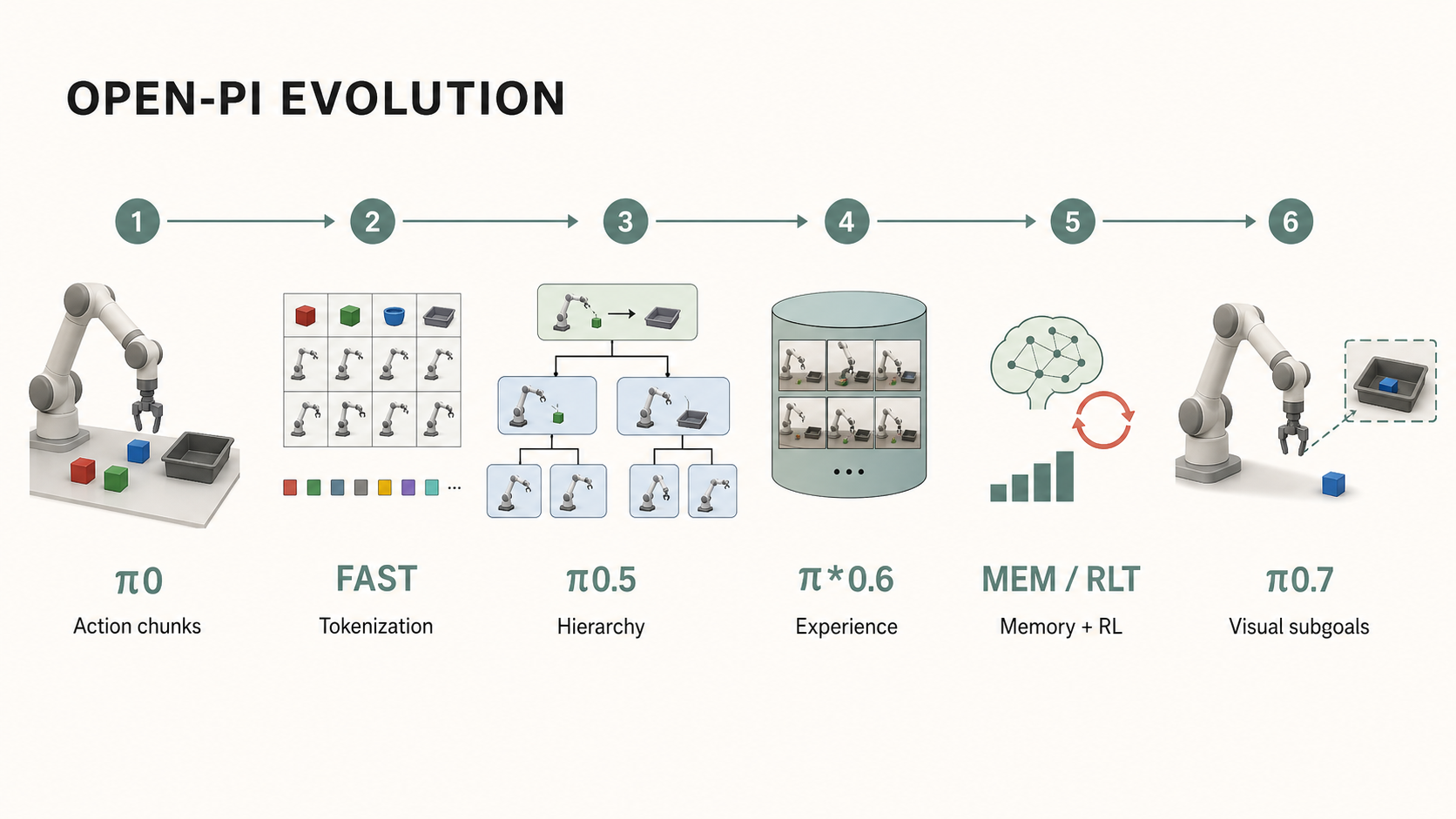
The open-pi line evolves a vision-language-action policy by improving continuous action generation, embodiment transfer, contextual generalization, memory, reinforcement feedback, and visual subgoal conditioning.
- Flow-matched action chunks preserve continuous control structure better than long sequences of discretized actions.
- General robot policies need shared semantic knowledge plus embodiment-specific action interfaces.
- Later open-pi models become more steerable by adding context, memory, experience, and visual subgoals.
A robot foundation model has to live with a strange split personality.
On one side, it needs the broad semantic understanding we now expect from visual-language models. Consider the instruction "put the mug next to the plate": the system must recognize the mug, parse "next to," know that plates are flat objects on tables, and track the instruction as the scene changes. That is familiar territory for anyone who has worked with VLMs.
On the other side, the robot cannot act like a chatbot. It cannot produce motor commands one token at a time. A real arm needs smooth, continuous, high-frequency control. It must move while cameras stream new observations, while objects slip, while latency accumulates, and while the world refuses to wait for the next token.
This is the central tension behind Physical Intelligence's open-pi line. From π0 in October 2024 to π0.7 in April 2026, the series is not just a story about larger models or better demos. The reason I find it worth reading as a sequence is that each release makes one more part of the robot problem explicit.
I use "open-pi sequence" as a reading lens rather than an official taxonomy. Some of these works are model releases, some are infrastructure releases, and some are research techniques that attach to the π model family. The arc below is my tutorial synthesis, not a claim that Physical Intelligence published one strict version roadmap.
The question keeps changing form, but it is roughly this:
What should a generalist robot policy be allowed to condition on, and how can it use that condition without giving up responsive physical control?
That is the lens I find most useful. π0 introduces an architectural boundary between pretrained visual-language representations and a continuous flow-matching action expert. FAST asks how action can be represented compactly enough for language-model-style training. OpenPI packages the π0-style architecture into an open-source adaptation and fine-tuning ecosystem. Hi-Robot and π0.5 add task decomposition, web knowledge, cross-embodiment data, and open-world context. Knowledge Insulation protects the VLM backbone from the wrong gradients. Real-Time Chunking treats latency as part of the control problem. π*0.6, Human2Robot, MEM, and RLT add experience, human demonstrations, long-term textual notes about task progress, short-term visual observation memory, and online refinement. π0.7 then makes the policy steerable through richer metadata and visual subgoals — including, in one inference mode, subgoals generated by a world model.
That sounds like a lot because it is a lot. But the pattern is simple: open-pi is progressively turning hidden sources of variation into things the policy can see and use.
The policy starts with an instruction and an observation. By the end of the sequence, it can also condition on subtasks, data provenance, action quality, corrections, embodiment variation, language summaries of task progress, short-term visual memory, reward feedback, execution timing, and — in visual-subgoal-conditioned modes — an image of the near future it should try to realize.
This essay is a tutorial reading of that arc. It aims to make the method sequence legible to readers who understand transformers, VLMs, fine-tuning, and reinforcement learning, but may not yet think in robot-control terms. It does not try to reproduce every experimental detail.
Throughout, I use VLA in the standard sense: a vision-language-action model — one that connects visual-language context to robot actions.
I read the official releases alongside a few external explainers: Hugging Face's π0/π0-FAST tutorial for VLA and action-representation framing, Cloderic's notes on π0 for architecture and data-recipe grounding, and Roboflow's VLA overview for broader "VLM plus action" context. Short-form X material — including Physical Intelligence's official account — is treated as an announcement trail rather than primary evidence; the stable claims are in the official posts and papers. The goal is to connect the releases into one design argument, not to summarize each paper in isolation.
Part 1: Action Interfaces
The first problem is deceptively basic. How does a model that understands images and language produce robot motion?
If the output were text, the answer would be straightforward: train the model to predict the next token. If the output were a single label, the answer would also be familiar: classify the scene or select an action from a discrete set. A robot arm does not fit either pattern. It needs a stream of continuous commands: joint targets, end-effector poses, gripper states, or some other robot-specific action representation.
The open-pi sequence begins by giving a pretrained visual-language backbone a continuous motor-output path.
π0: Put Meaning in the Backbone and Motion in the Expert
π0, announced on October 31, 2024, starts from a sensible premise: a robot should not relearn the visual and semantic world from scratch. A pretrained VLM already knows a great deal about objects, language, spatial relations, and common situations. Throwing that away would be wasteful.
But there is an immediate problem. A pretrained VLM is good at representing the world; it is not naturally a high-frequency controller. If we ask it to emit a long sequence of discretized motor tokens, we force physical movement into a format designed for language. If we ask it to output only a high-level plan, we still need another system that can make the arm actually move.
π0's answer is to keep the VLM backbone and attach a continuous action expert.
The mental model is close to how we divide a human instruction. "Pick up the orange bowl" requires semantic recognition: which object is the orange bowl, where is it, what does "pick up" imply? But the actual reaching motion is not a sentence. It is a smooth trajectory through space, with timing, grip closure, and correction as the hand approaches the object.
π0 makes that boundary explicit without cleanly separating thinking and acting into independent modules. The model receives camera observations, a language instruction, and robot state. More precisely, pretrained VLM representations provide visual-language context, while the added action expert — trained with flow matching — gives the policy a continuous motor-output path.
An action chunk is simply a short horizon of commands predicted at once:
Here
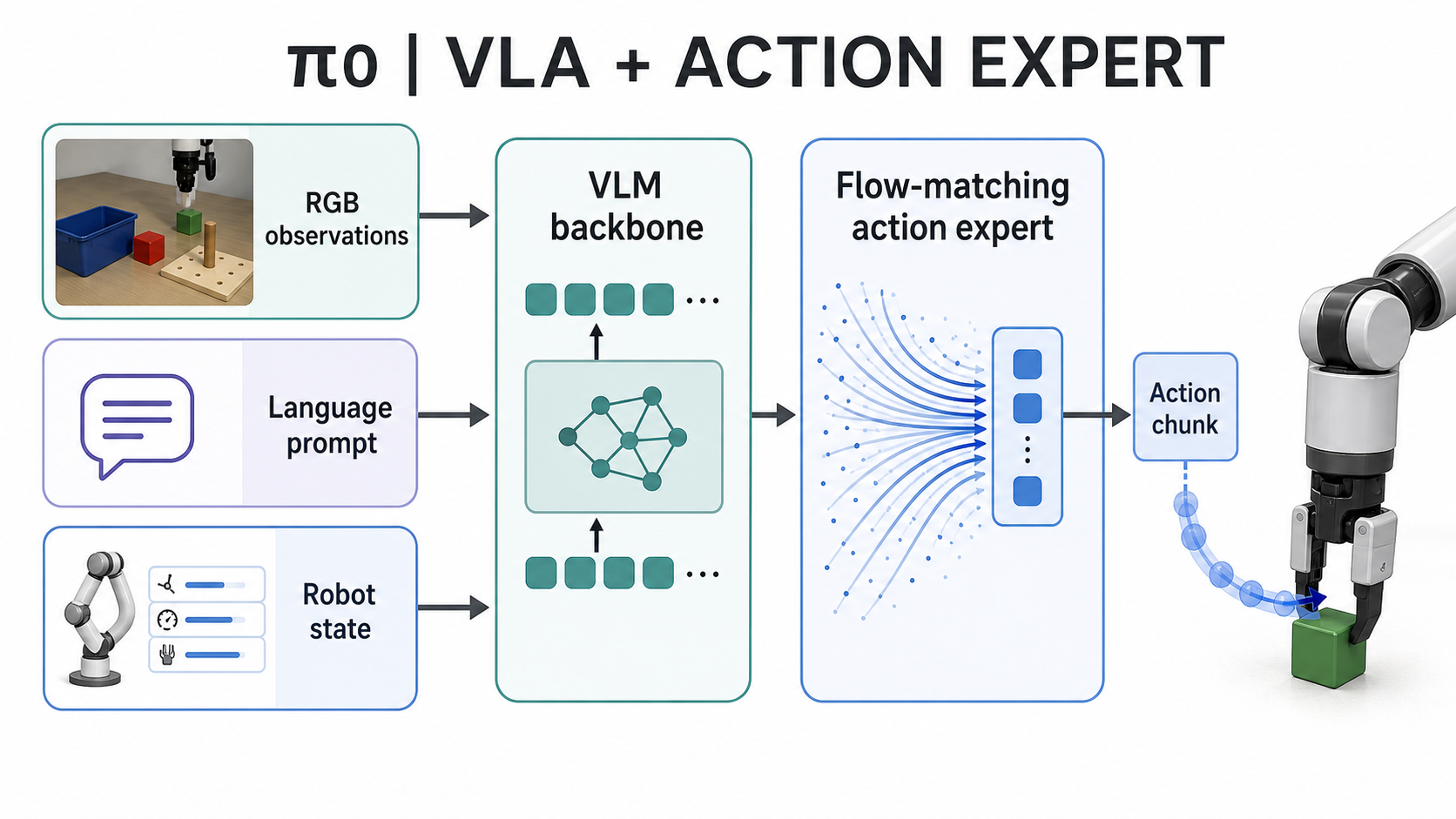
The official π0 post describes a roughly 3B-parameter pretrained VLM that emits continuous action chunks at up to 50 Hz. It also describes a training mixture that combines internet-scale visual-language pretraining, open robot data, and Physical Intelligence's own multi-robot dexterous dataset. The internal robot data spans eight robot configurations and includes tasks such as bussing tables, folding laundry, assembling boxes, packing groceries, and handling cables.

This is a real interface problem, not a cosmetic architectural choice. π0 lets the model inherit broad visual-language knowledge while still producing smooth continuous control. It also introduces the next problem. A chunked policy still has to decide when and how to generate the next chunk. If inference is slow, the robot may be acting on a trajectory planned from an old observation. π0 shows how to connect a VLM to action; it does not by itself solve real-time replanning.
That tradeoff will return later in Real-Time Chunking.
FAST: Compress Motion Before You Ask a Transformer to Predict It
π0 uses continuous generation because simple binning-based action tokenization is a poor fit for high-frequency dexterous motion. But that does not mean tokens are useless for robot actions. It means bad action tokens are useless.
FAST, published on January 16, 2025, makes this distinction precise. The problem is not that autoregression is inherently incompatible with robot learning. The problem is that naive tokenization wastes sequence length on the wrong things.
Imagine recording the motion of a robot arm as it reaches toward a cup. Across a short time window, most coordinates change smoothly. The wrist does not teleport. The gripper does not randomly jump from open to closed. Consecutive actions are highly redundant.
A naive autoregressive VLA ignores this structure. It bins each action dimension independently and then asks the model to predict a long list of small per-dimension values. A seven-dimensional action emitted at 20 Hz over one second can require 140 action tokens. At higher frequencies or longer horizons, the sequence gets worse. The transformer spends its budget describing tiny local changes that could have been summarized more compactly.
FAST treats the action chunk like a compressible time series. Its pipeline is:
- Normalize each action dimension using robust dataset quantiles.
- Apply a Discrete Cosine Transform (DCT) along time.
- Quantize the frequency coefficients.
- Flatten the coefficients in low-frequency-first order.
- Apply byte-pair encoding (BPE) so common coefficient patterns become compact action tokens.
The DCT step carries the main idea. Smooth motion is dominated by low-frequency structure. The broad reach toward the cup matters first; the small corrections near the end matter later. By representing the trajectory in frequency space, FAST can spend early tokens on the shape of the movement rather than restating every coordinate at every time step.
Physical Intelligence reports typical chunks of 30 to 60 FAST tokens, roughly a 10x compression over prior action tokenizations, and says π0-FAST trains up to five times faster than the original π0 while approaching its dexterity. FAST+ then extends this idea into a broader tokenizer trained on roughly one million real robot action sequences across multiple robot types.
FAST has two roles in this sequence. First, as π0-FAST, it enables a fully autoregressive VLA to learn dexterous action chunks through next-token prediction. Second, in Knowledge Insulation, FAST-tokenized actions become a representation-learning objective for the VLM backbone, while the continuous action expert remains the fast execution path.
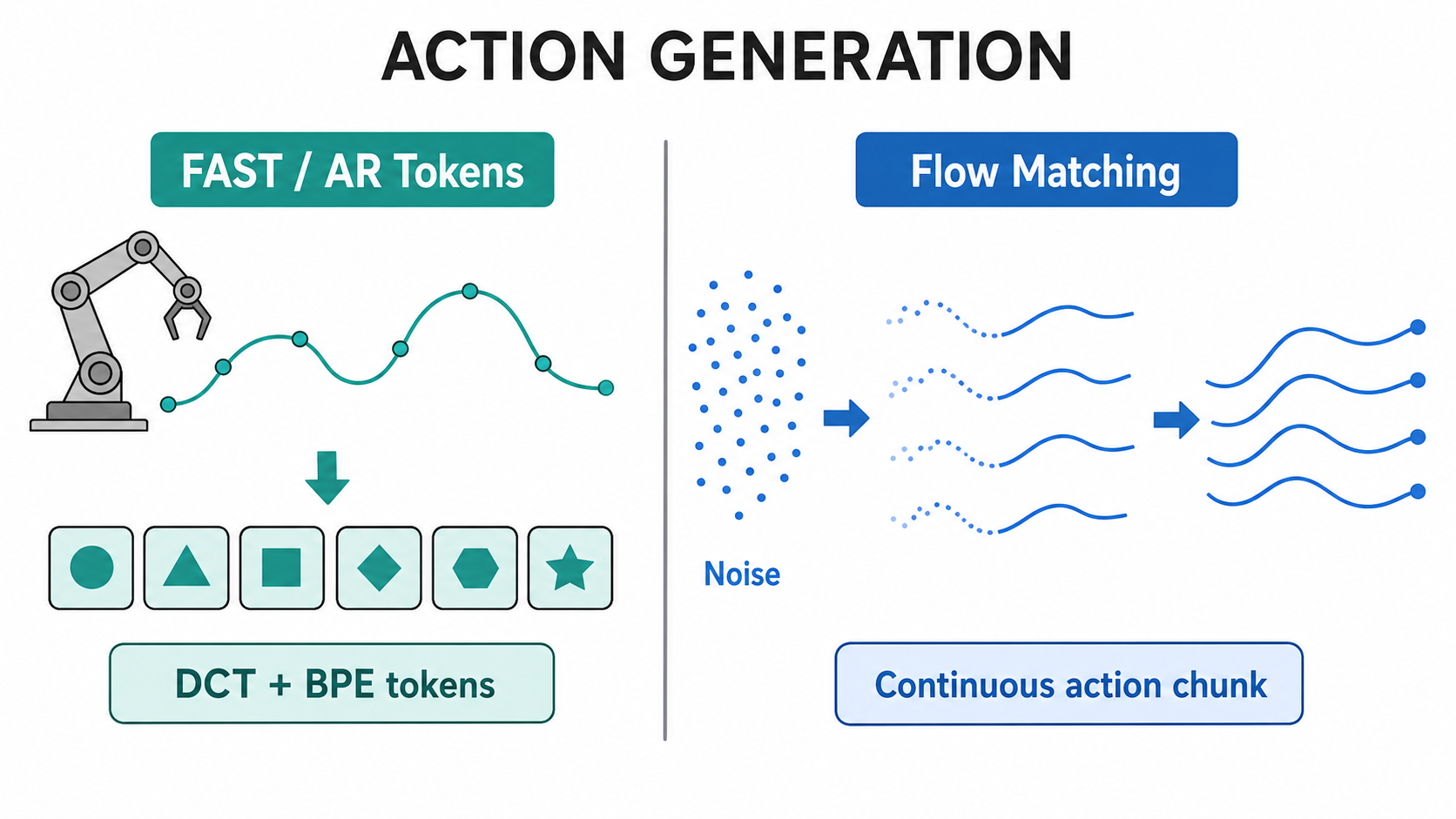
The useful reading is not "tokens beat flow" or "flow beats tokens." They solve different interface problems.
FAST helps when the backbone needs to learn action structure using language-model-compatible objectives, and π0-FAST is itself an autoregressive policy rather than just an auxiliary trick. Flow matching helps when the final controller needs to emit smooth continuous motion. Later work uses these ideas together: FAST-tokenized action objectives can adapt the VLM representation, while a continuous action expert remains the execution path and the discrete action-token path can be discarded after training.
The limit is just as important. FAST makes action more learnable for autoregressive models, but it does not remove the need for a controller that respects real-time physical constraints. Compression helps the model learn; it does not by itself make the robot responsive.
OpenPI: Turning the Architecture Into an Open Adaptation Recipe
The Open Sourcing π0 release makes the architecture more concrete. It is not only a checkpoint announcement. It is a recipe for adapting π0-style policies across embodiments and datasets.
This matters because "generalist robot policy" can sound too abstract. In practice, every robot has its own cameras, calibration, action space, state representation, gripper conventions, dataset format, and task distribution. A policy that only works inside one lab setup is not really a foundation model in the useful sense.
OpenPI separates the adaptation problem into surfaces an engineer can actually work with:
| Concern | Method-level role |
|---|---|
| Backbone reuse | Preserve broad visual-language representations instead of training robot perception from scratch. |
| Action adaptation | Fine-tune the action expert and policy boundary around the target robot's state/action format. |
| Dataset portability | Treat robot data loading, normalization, camera views, and task labels as configurable adaptation surfaces. |
If I move from one arm to another, the meaning of "pick up the towel" should not have to be relearned from zero. The camera geometry and action coordinates may change, but the semantic problem is still recognizable. OpenPI tries to make that separation usable: reuse the broad backbone, adapt the motor side, and make the dataset plumbing explicit enough that new embodiments can be brought into the same family.
Adaptation is still adaptation. OpenPI does not magically remove embodiment differences. It gives a structured path for moving a policy into a new robot and dataset regime. That is already important. In robotics, the boring-looking integration work is often what determines whether a model family becomes reusable or remains a collection of isolated demonstrations.
At this point, the first part of the open-pi story is visible. π0 gives a VLM a continuous motor path. FAST gives action structure a compact token form for training. OpenPI gives the resulting model family a way to move across robot setups.
The next problem is not motion. It is context.
Part 2: Generalization Through Context
A robot that can move smoothly is still far from useful in an ordinary home or workplace.
"Clean the table" is not a low-level action. It is a loose instruction that may require recognizing objects, deciding what counts as clutter, choosing an order, asking for clarification, moving around occlusions, and recovering from mistakes. The robot needs more than visual recognition and motor control. It needs a way to turn open-ended intent into executable physical steps.
This is where the open-pi sequence starts moving upward and outward: upward into hierarchy and subtasks, outward into web knowledge, other environments, other embodiments, and richer training mixtures.
Hi-Robot: From "Do This" to "Break This Down"
Hi-Robot, published in February 2025, addresses a bottleneck that becomes obvious once manipulation works at all. A user does not want to issue every motor-level instruction. They want to say something like "tidy this area" or "put the dishes away."
Even a physically competent low-level policy struggles here. The problem is not execution alone; it is task interpretation. What should be picked first? Which objects belong together? Should the robot speak back? What happens when the human corrects it?
Hi-Robot places a high-level VLM above a low-level π0-style VLA. The high-level model receives open-ended instructions, observations, and possible human intervention. It can produce verbal responses or simple language subtasks. The low-level policy executes those subtasks as physical movement.

The analogy to ordinary work is useful here. If someone says "clean the kitchen," you do not translate the sentence directly into muscle commands. You decompose it: clear the counter, move dishes to the sink, put food away, wipe surfaces. A robot needs some version of that decomposition before low-level control becomes useful.
Hi-Robot is therefore less about a new motor representation and more about interaction. It lets language operate at the level where language is strongest: task structure, clarification, and correction. The low-level VLA handles the part where continuous control is strongest.
The cost is coordination. Once a system has a high-level policy and a low-level policy, errors can happen at either level. The high-level model can choose the wrong subtask; the low-level policy can execute a good subtask poorly. But the hierarchy is still valuable because it places the burden of open-ended interpretation somewhere more appropriate than the motor controller.
π0.5: Open-World Generalization Needs a Wider Training Diet
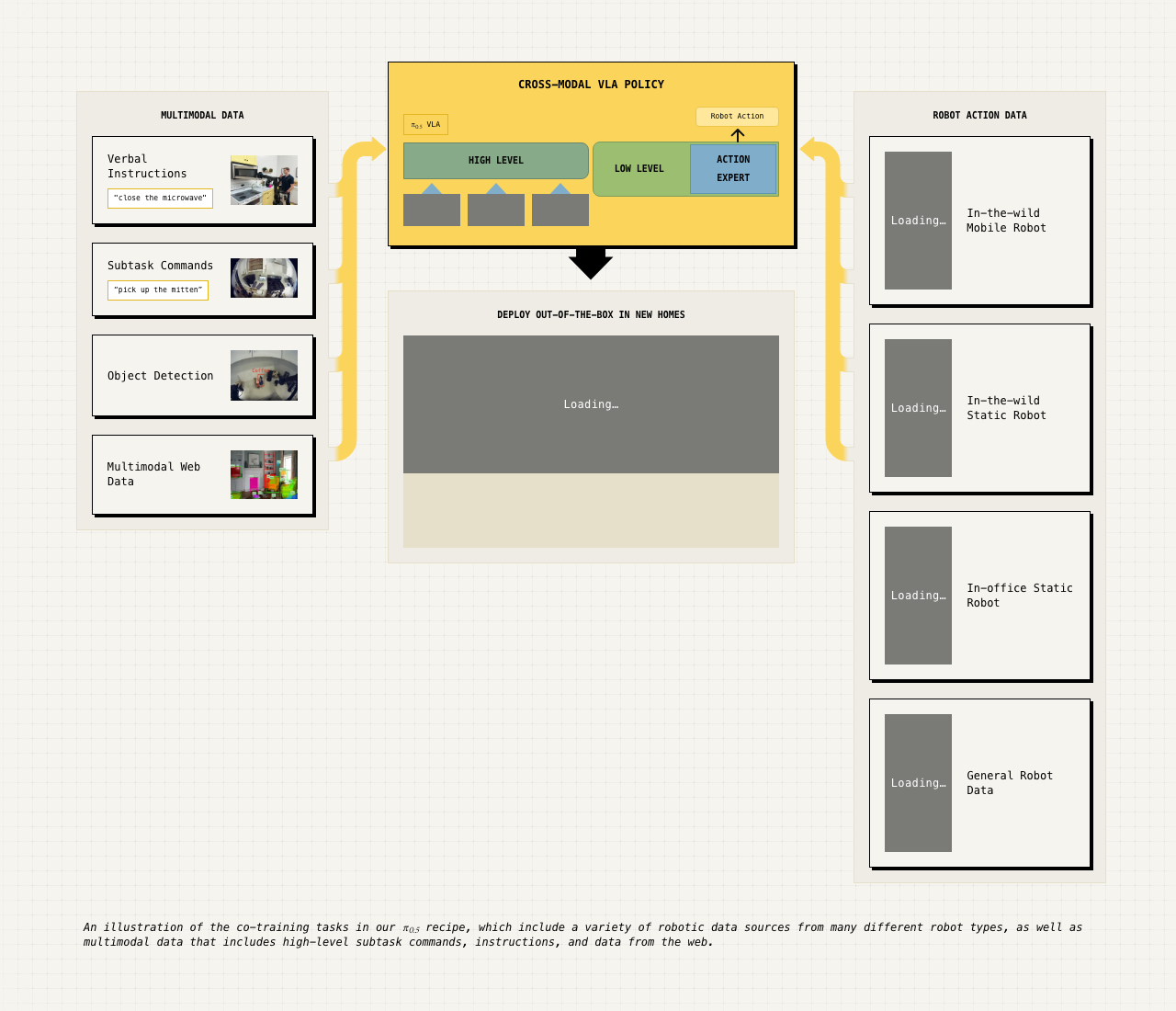
π0.5, published on April 22, 2025, consolidates the hierarchy idea into a single VLA designed for open-world generalization. The goal is not just dexterity in familiar settings. It is long-horizon cleaning and rearrangement in homes and object configurations outside the robot training set.
It might seem that a large enough robot dataset would automatically produce generalization. π0.5 is more specific: it treats generalization as a context problem. The model needs exposure to different environments, different robot embodiments, high-level task labels, and web-scale multimodal knowledge.
The mechanism is heterogeneous co-training. The official report organizes the training mixture around complementary signals:
| Data signal | Role in π0.5 |
|---|---|
| Mobile manipulator data (MM) | Long-horizon household behaviors in mobile settings |
| Multiple-environment non-mobile data (ME) | Physical skills across varied scenes |
| Cross-embodiment data (CE) | Transfer from multiple robot morphologies |
| High-level subtask / verbal instruction data (HL) | Task decomposition and interactive language following |
| Web multimodal data (WD) | Object/category knowledge, VQA, grounding, captioning and detection |
A useful way to read the mixture is that each source patches a different generalization hole. Mobile manipulation data teaches long-horizon household behavior. Multiple environments reduce overfitting to one room. Cross-embodiment data can be read as pressure for the model to represent behavior above the quirks of a single robot body. High-level labels teach task decomposition. Web data gives the model broader object and category knowledge than robot data alone can provide.
The official ablations make the point concrete. For the OOD evaluation reported in the release, full π0.5 reaches 94% follow rate and 94% success rate. Removing web multimodal data drops those numbers to 80% and 74%. Removing cross-embodiment data yields 67% and 49%. Removing multiple-environment robot data yields 33% and 31%.
The exact numbers are less important than the shape of the result. Generalization is not coming from one magic source. Web knowledge helps the robot recognize unfamiliar objects. Cross-embodiment and multi-environment data help prevent the policy from binding behavior too tightly to one robot or one room.
At inference, π0.5 first predicts a high-level language action and then conditions the continuous action expert on the current observation, the original instruction, and that subtask. Unlike the two-model Hi-Robot arrangement, π0.5 uses one VLA for both steps.
One compact way to read this is:
This is not meant as the literal implementation; it is a tutorial factorization that expresses the interface.
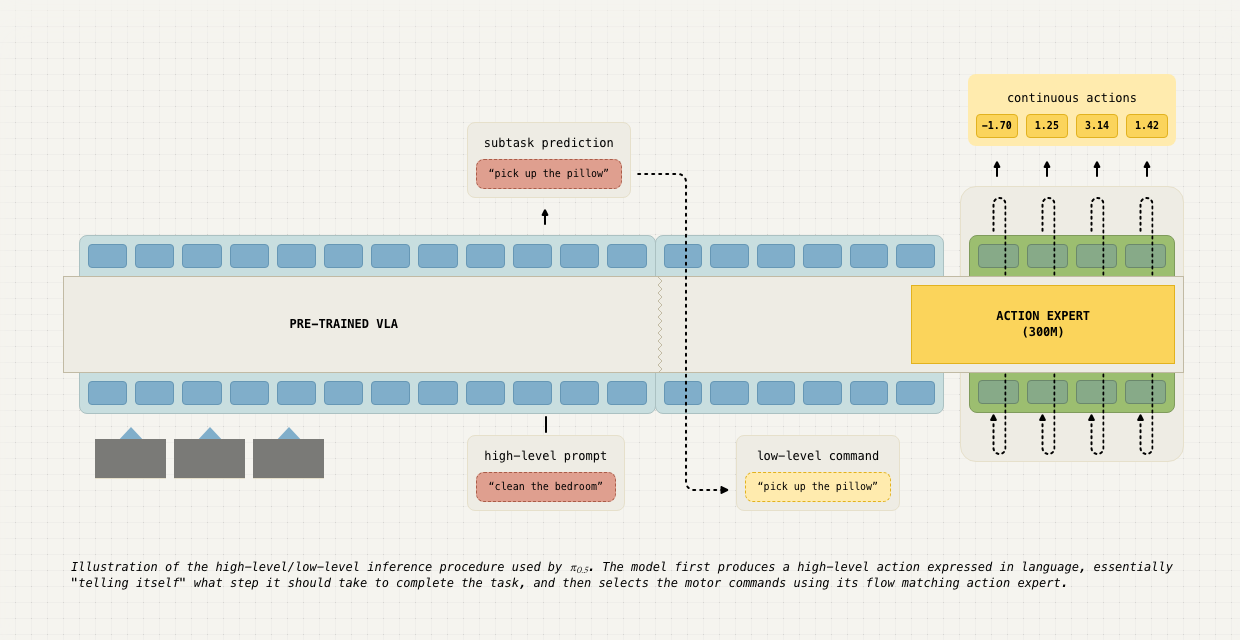
Here open-pi stops looking like a VLM with a motor head attached. It becomes a system for making task context explicit. The instruction is no longer expected to directly determine every low-level action; it is decomposed into a subtask, and that subtask becomes one of the conditions for continuous control.
Richer context also creates a harder training problem. Mixing web data, robot action data, high-level labels, and multiple embodiments is not just "more data." The model has to learn which signal matters at which level. If the mixture is poorly organized, the policy can become confused rather than general.
Knowledge Insulation: Do Not Let Motor Gradients Break Semantics
Once a VLM becomes a robot policy, another failure mode appears. The robot objective can damage the knowledge that made the VLM useful in the first place.
VLAs that Train Fast, Run Fast, and Generalize Better, published on May 28, 2025, frames the action expert as a new "motor cortex" attached to a pretrained VLM. The metaphor is apt: if the motor cortex sends the wrong learning signal into the rest of the system, semantic representations can drift.
The naive approach would be to train the whole model end-to-end with a continuous action loss. That sounds clean, but the loss is not necessarily friendly to language-sensitive knowledge. A continuous motor objective might push internal representations toward whatever helps fit the robot dataset, even if that weakens object recognition or instruction following. In the official examples, naive continuous-action adaptation can make a robot attend to the wrong requested object.
Knowledge Insulation (KI) creates a boundary:
- The VLM backbone adapts through language/web objectives and FAST-tokenized robot-action prediction.
- The continuous action expert attends to the backbone and learns flow-matching control.
- Gradients from the continuous action expert are stopped before they enter the VLM backbone.
- FAST tokens are discarded at inference; the action expert supplies the actual continuous command.
The goal is not to freeze the VLM forever. A frozen backbone may preserve semantic knowledge, but it may not learn robot-relevant features. The better move is to adapt the backbone through objectives that are compatible with the kind of knowledge we want it to keep. FAST-style action tokens can teach the backbone about action structure in a token-prediction format. The continuous flow-matching expert can then learn motor control without pushing its gradients back into the semantic backbone.
KI is one of the cleanest examples of the larger pattern. It asks which learning signal should cross which boundary. Semantic representations should become robot-aware, but not by being directly overwritten by a continuous control loss.
The price is architectural complexity. KI adds a distinction between representation adaptation and execution training. But that distinction matches the problem. A generalist VLA is valuable because it combines broad knowledge with motor skill. If the motor objective destroys the broad knowledge, the model has won the wrong game.
Real-Time Chunking: The Robot Moves While the Model Thinks
The other failure mode is temporal. Even if a policy predicts good action chunks, those chunks may not arrive in time.
Real-Time Action Chunking, released on June 9, 2025, starts from a concrete control problem. A large policy may take nontrivial time to generate the next chunk. During that time, the robot is not frozen in an abstract simulator. It is executing the previous chunk. By the time the new chunk is ready, the physical state has changed.
If inference latency is
Here
The exact floor operation is less important than the physical meaning: by the time the successor chunk becomes available, the first
A synchronous policy can pause at chunk boundaries while waiting for inference. That is bad for smooth real-time control. A naive asynchronous policy can generate the next chunk while the previous one executes, but it may switch onto a trajectory inconsistent with the movement already underway. Temporal ensembling can blur incompatible futures rather than solve the timing problem.
RTC reframes successor-chunk generation as inpainting. When generating the next chunk, the first

This works naturally for diffusion or flow policies because they already generate trajectories through iterative denoising and can incorporate constraints during generation. The official presentation describes RTC as training-free, with one worker executing current actions while another generates a compatible successor chunk.
RTC does not make the model faster in the ordinary sense. It makes the control loop respect the fact that computation and execution overlap. That is a more robotics-specific kind of speed: not only reducing milliseconds, but making delayed decisions consistent with the motion already happening.
By the end of Part 2, the policy has more than a motor path. It has a subtask layer, a data-mixture strategy, a protected representation boundary, and a real-time execution scheme.
The next step is to make experience itself legible.

Part 3: Experience, Memory, and Future Conditions
Robot data has a stubborn asymmetry. It is expensive to collect, but extremely informative when it comes from real deployment. A robot in the world produces successes, failures, near misses, human interventions, repeated attempts, and local corrections. Ordinary behavioral cloning often flattens those distinctions. It treats a trajectory as something to imitate or not imitate, without always preserving why it was good or bad.
The later open-pi work makes those distinctions more explicit. Experience becomes a training signal the policy can condition on. Human data becomes useful after broad robot pretraining. Memory gets split into language summaries of task progress and short-term visual memory. Online RL refines the difficult local phase. π0.7 then turns future visual states into one supported form of control target.
π*0.6 and RECAP: Failed Rollouts Are Not Just Bad Demonstrations
π*0.6, published on November 17, 2025, introduces RECAP: Reinforcement Learning with Experience and Corrections via Advantage-conditioned Policies.
The problem is easy to state. Once robots are deployed, they collect messy data. Some autonomous rollouts succeed. Some fail. Some fail until a human intervenes. Some contain partial progress followed by a correction. If we simply imitate everything, we teach the policy to copy bad behavior. If we throw away failures, we waste information about what went wrong.
RECAP turns experience quality into an input condition. A value function estimates which behavior improved the outcome, and the policy is trained with an advantage label such as:
Advantage: positive
Advantage: negativeAt inference, the policy can be prompted toward positive-advantage behavior.
The analogy is an edited draft with tracked changes. The bad version shows where the model tends to go wrong. The correction shows what better behavior looked like. The advantage label makes that relation legible to the policy.
RECAP is organized in three stages:
- Offline RL pretraining: train a value function from broad robot demonstrations, then train a π*0.6 policy conditioned on inferred advantage.
- Task-specific supervised fine-tuning: adapt to tasks such as laundry or box assembly using successful demonstrations as positive behavior.
- Iterative improvement: deploy, collect autonomous rollouts and interventions, relabel the expanded dataset using the updated value function, retrain, and redeploy.

That changes the status of failure data. A failed rollout is not automatically worthless imitation data; paired with a correction, it marks inferior behavior and helps train a policy that can be steered after deployment.
The weakness is that advantage labels depend on the quality of the value estimation and relabeling process. RECAP does not remove the difficulty of evaluating robot behavior. It gives the policy a way to use that evaluation once it exists.
Human2Robot: Human Demonstrations Help After the Robot Prior Is Broad Enough
Robot data is expensive. Human demonstrations are abundant. The temptation is obvious: use human video to teach robots. The difficulty is also obvious: human hands are not robot grippers, human bodies do not share robot kinematics, and human videos do not contain robot joint commands.
Emergence of Human to Robot Transfer in VLAs, published on December 16, 2025, asks whether a sufficiently broadly pretrained π0.5 can already align human and robot behavior well enough to learn from both.
Crucially, the human data is not casual internet video. It consists of egocentric human demonstrations with task and subtask structure, co-trained with robot demonstrations. The official release claims that transfer emerges from broad VLA pretraining without requiring a bespoke alignment method for every new behavior.
The reported transfer is conditional, not a rule that human data will always help. If a robot model has seen one narrow embodiment and task distribution, a human demonstration may remain too far away in action space, viewpoint, timing, or contact dynamics. Broader robot pretraining can make the overlap more usable, but it does not remove the need to test the transfer on the target embodiment and task.
The official project page reports roughly a 2x improvement over four generalization scenarios when egocentric human data is included in fine-tuning. The scaling observation is more important than the single number: benefits from human data become stronger as robot pretraining becomes more diverse, and official visualizations show human and robot features aligning more closely with broader pretraining.
Human data is therefore not a cheap replacement for robot experience. It is a capability amplifier after embodiment-grounded robot pretraining has done enough work. This constraint is worth keeping in view because it prevents the story from collapsing into "just train on videos of humans." The representation has to make human behavior robot-relevant before the data becomes valuable.
MEM: Long Progress and Local Geometry Are Different Memories
A reactive VLA can manipulate what it sees right now. A robot cleaning a kitchen for fifteen minutes needs something more. It must remember which cupboard has already been handled, whether a failed grasp should be retried differently, and where an object went after it became occluded.
MEM: Multi-Scale Embodied Memory, released on March 3, 2026, equips π0.6 with two different kinds of memory because these needs are not interchangeable.
The obvious answer would be to extend the context window and feed in more history. That is not enough. Some history should become language because it is semantic progress: "the bowls are already in the cabinet." Other history should remain visual because it contains geometry: the utensil was partly hidden by the gripper, the cloth edge folded under itself, the cup shifted slightly after contact.
MEM splits the problem:
| Timescale | Representation | Used for |
|---|---|---|
| Long-term | Language memory summary | progress, completed operations, high-level subtask selection |
| Short-term | Compact video memory | occlusion, local geometry, corrective manipulation |
Long-term language memory compresses task progress into a form useful to a high-level policy. The robot does not need every frame of placing three bowls into a cabinet; it needs the fact that those bowls are already there.
Short-term memory is visual. If a failed grasp should be corrected using slightly different geometry, language may be too lossy. A compact visual trace can preserve local evidence that matters for physical correction.
The official page says MEM enables tasks up to fifteen minutes long, partial-observability handling, and in-context correction of manipulation strategies.
Memory is not free context. It is a representational choice: what should be summarized, what should remain visual, and which policy level should read it? MEM's answer is strong because it refuses to treat memory as one undifferentiated buffer.
RLT: Use a Strong VLA as a Prior for Local Online Learning
RLT: Precise Manipulation with Efficient Online RL, published on March 19, 2026, focuses on a different kind of limitation. A generalist VLA may be good enough to approach a task, but not precise enough for the contact-rich final phase: fastening a zip tie, inserting a screw, or plugging in an Ethernet connector.
The naive RL solution would be to train the whole VLA online. That is expensive and risky. The model is large, the reward may be sparse, and the useful exploration space near contact is narrow.
RLT instead treats the VLA as a representation and behavior prior while a smaller online learner improves local behavior. The objective below is a schematic view of regularized improvement, not the full paper loss. The refinement balances reward against movement away from the VLA proposal:
The control idea is simple: improve the local action, but do not drift too far from the generalist policy's proposal.
The VLA gets the robot to the right neighborhood. It understands the task, scene, and broad manipulation strategy. The small online learner then specializes on the last hard millimeters, where contact dynamics and precision matter more than broad semantic knowledge.
This gives the VLA three roles: representation, behavior prior, and constraint on risky exploration. The official RLT release reports rapid online improvement on tasks including zip-tie fastening and screw insertion.
The key limitation is scope. RLT is not trying to make online RL solve all of general robotics. It concentrates online improvement on the phase where a generalist policy is weakest. That is a more realistic use of reinforcement learning: local refinement around a strong prior, not a replacement for the foundation model.
π0.7: Make the Desired Future Visible
π0.7, published on April 16, 2026, makes the accumulated direction explicit in its title: a steerable generalist robotic foundation model.
The problem is that a natural-language instruction often underspecifies the physical future. "Put the food on the table" may be clear enough semantically, but it does not specify the intermediate grasp geometry, the angle of an opened door, the intended near-future pose of a plate, or the visual state that should exist in a few seconds.
π0.7 expands what can be placed in the prompt. A conventional prompt might contain:
Task: clean the kitchen
Subtask: open the fridgeThe official π0.7 release describes conditions that can also specify aspects of behavior quality and history, along with subgoal images. Real robot datasets mix many kinds of behavior: quick and clumsy demonstrations, slow and careful demonstrations, successful and failed attempts, human-directed episodes, and autonomous rollouts. Without labels, the model is encouraged to average incompatible behaviors. Metadata gives the policy a way to learn the distinctions and request the appropriate regime at inference. A Zhihu reading of π0.7 pushes this point in a sharper direction: mixed-quality data becomes more usable when quality itself is represented, though I would not turn that into the stronger claim that data cleaning no longer matters.
Architecturally, π0.7 extends the context available to a continuous-action VLA: observations and language can be joined by history, metadata, and visual subgoals.
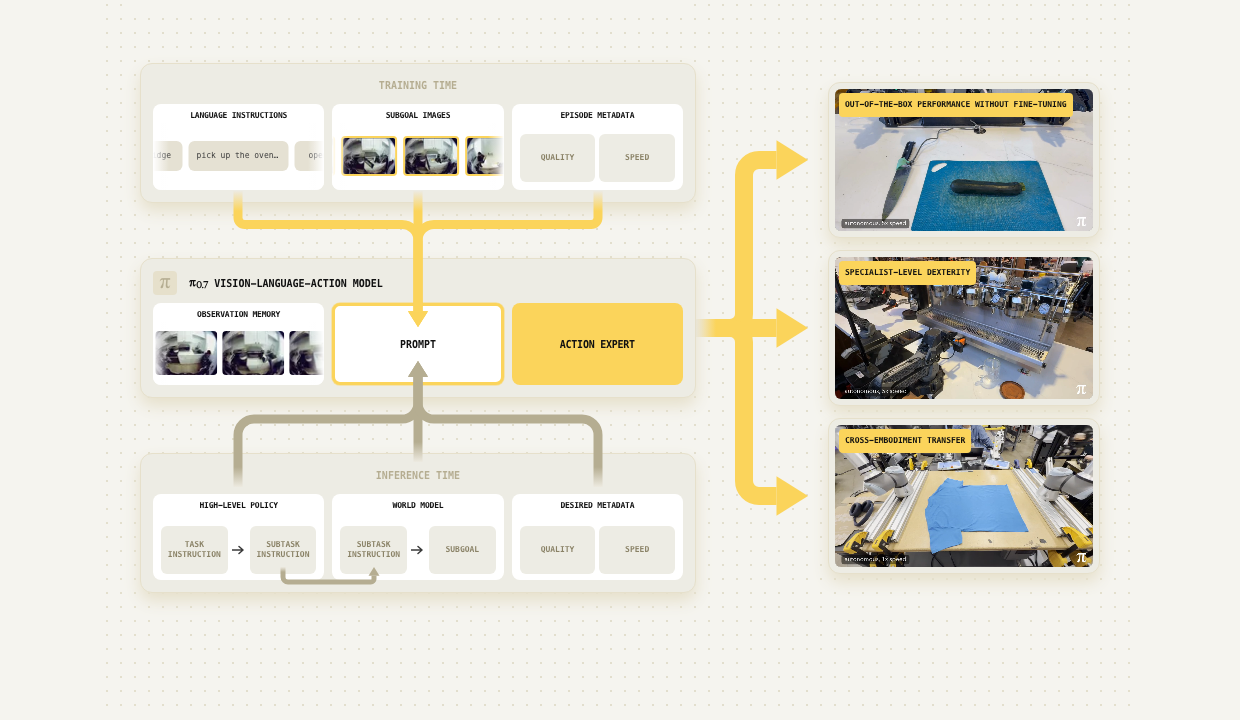
A notable addition is the subgoal image. In one inference mode, a lightweight world model generates visual subgoals from the current observation and subtask. π0.7 can then condition on those subgoal images, though visual subgoals are one supported prompt modality rather than the only way the policy operates.


The official release presents emergent capabilities including complex-instruction following, counterfactual steering, cross-embodiment behavior, and stronger execution when high-level policies provide subgoals. External discussion has understandably focused on the "generalist versus specialist" reading: in the reported RECAP-style settings, π0.7 approaches or matches task-specific RL-trained specialists. I would read those claims carefully. They do not mean steerability has solved robustness, and they should not be generalized to every SFT or RL specialist. They show why richer control signals are worth taking seriously.
That caveat is not only academic. A Reddit robotics discussion around π0.7 asks the questions release demos usually cannot settle: repeatability across runs, sensor noise, actuator backlash, hardware wear, surface friction, and failure behavior when the model leaves the distribution. I read that skepticism as pressure on the deployment claim, not as a dismissal of the research result.
The method-level reading is narrower and more durable: π0.7 turns prompting into a structured control surface. Language names the task. Metadata selects behavior style or data regime. Control modality labels specify how actions should be interpreted. Memory carries context across time. Visual subgoals, including world-model-generated subgoals in some settings, supply physical detail that language would underspecify. The policy is still a continuous-action controller, but the target it acts toward is no longer only a sentence.
The risk in the world-model-generated subgoal mode is that a generated target becomes part of the control stack. If the subgoal is wrong, the VLA may be steered toward the wrong future. The upside is the same property seen from another angle: the desired future becomes explicit enough to inspect, condition on, and improve.
What the Open-pi Sequence Actually Teaches
It is tempting to frame robotics foundation models as a competition between tokens and flow matching, hierarchy and end-to-end learning, imitation and reinforcement learning, or language prompts and visual goals. I think the open-pi sequence points to a better framing.
The question is not which representation wins everywhere. The question is which representation belongs at which boundary.
Autoregressive action tokens can serve as a policy interface and help a backbone absorb action structure through language-model-compatible training. Flow matching keeps the final motor signal smooth and continuous in π0-style action-expert models. Hierarchy turns open-ended human intent into executable subtasks. Knowledge insulation protects inherited semantics from motor gradients. Real-time chunking (RTC) bridges the gap between large-policy latency and physical time. Advantage conditioning turns deployment experience into a policy-visible signal. Human data helps after broad robot pretraining establishes a transferable prior. MEM separates long-term textual task-progress memory from short-term visual observation memory. RLT uses a VLA as a prior for a smaller online learner. Visual subgoals specify desired physical states that language leaves vague.
The unifying change is that more of the robot's relevant world becomes explicit and controllable. Instead of asking a monolithic policy to infer every distinction from pixels and language alone, these works expose selected distinctions as policy-visible inputs: action format, task level, data source, execution timing, correction, memory, reward, and desired future.
That is why π0.7 is a useful endpoint for this reading sequence, not a claim that the research problem is complete. The early question was how to obtain continuous robot action from a VLM. The later question is how to give a capable continuous controller the right context at the right time, then measure whether that context improves repeatable task execution.
The broader hypothesis is narrower than "scale will solve robotics": some variables should be made controllable rather than left for one input-output mapping to discover implicitly. The test is empirical. Does an active task, subtask, quality label, episode history, memory, correction signal, or visual subgoal improve success, recovery, latency, or transfer on the target robot without making the control loop brittle?
For perception-action learning, that is a more concrete version of the foundation-model ambition. A useful robot policy has to join perception, language, action, memory, feedback, and prediction while preserving the boundaries that let engineers inspect and correct the system. The open-pi sequence is valuable because it makes several of those boundaries visible, and because it makes the remaining integration problem harder to ignore.
Series Note
This essay is intentionally long because the pieces make more sense when the whole arc is visible. If I later turn it into a shorter series, I would split it along the same conceptual boundaries:
- How Robots Turn Language Into Motion: π0, action chunks, flow matching, FAST, and OpenPI adaptation.
- Why Generalist Robots Need More Context: Hi-Robot, π0.5, heterogeneous co-training, Knowledge Insulation, and RTC.
- Robots That Learn From Experience and Imagined Futures: π*0.6, Human2Robot, MEM, RLT, π0.7, and the final reflection.
Technical Reference Notes
The official releases below form a coherent engineering sequence. This appendix is meant as a lookup table, not a second version of the essay.
The quantitative results in the preceding sections are within-study comparisons. A 5x training claim for FAST, a 7.5x reduction in training steps for Knowledge Insulation, a 2x transfer result for Human2Robot, and an RTC latency result use different tasks, policies, hardware, and success definitions. They support the mechanism claimed by each study; they do not form a shared leaderboard across the π family.
| Work | Core interface | Why it matters |
|---|---|---|
| π0 | VLM backbone plus flow-matching action expert | Adds a continuous motor-output path to pretrained visual-language representations. |
| OpenPI | Open-source code, checkpoints, and fine-tuning recipe | Makes π0-style policies more reusable across robot setups. |
| FAST / FAST+ | Frequency-structured action tokens | Compresses smooth action chunks for autoregressive action-token policies and FAST-tokenized representation learning. |
| Hi-Robot | High-level VLM plus low-level VLA | Turns open-ended instructions and feedback into executable subtasks. |
| π0.5 | Heterogeneous co-training and subtask-conditioned action | Uses web data, multi-environment robot data, cross-embodiment data, and high-level labels for open-world generalization. |
| Knowledge Insulation | Gradient boundary between backbone and action expert | Lets the backbone adapt to robot-relevant structure without letting continuous control loss damage semantic knowledge. |
| RTC | Inpainted successor chunks under latency | Keeps chunked action generation compatible with physical execution while the robot is moving. |
| π*0.6 / RECAP | Advantage-conditioned policy from experience and corrections | Turns deployment outcomes into a condition the policy can use. |
| Human2Robot | Co-training with egocentric human demonstrations | Uses human behavior as an amplifier once broad robot pretraining creates a transferable prior. |
| MEM | Long-term textual task-progress notes and short-term visual observation memory | Separates semantic task progress from local geometric evidence. |
| RLT | Small online RL specialist around a VLA prior | Refines contact-rich precision phases without retraining the whole foundation policy online. |
| π0.7 | Structured steering with metadata conditioning, memory, control modalities, and visual subgoals | Lets a continuous-action policy act toward richer conditions, including world-model-generated subgoals in one supported inference mode. |
Citation
Please cite this article as:
Ji, Wenbo. “From π0 to π0.7: A Tutorial on Open-pi and Robot Foundation Models”. fusheng-ji.github.io (May 2026). https://fusheng-ji.github.io/blog/posts/from-pi0-to-pi07-open-pi-series/
Or use the BibTeX entry:
@article{ji2026frompi0topi07openpiseries,
title = {From π0 to π0.7: A Tutorial on Open-pi and Robot Foundation Models},
author = {Ji, Wenbo},
journal = {fusheng-ji.github.io},
year = {2026},
month = {May},
url = {https://fusheng-ji.github.io/blog/posts/from-pi0-to-pi07-open-pi-series/}
}References
- Physical Intelligence. π0: Our First Generalist Policy.
- Physical Intelligence. Open Sourcing π0.
- Physical Intelligence. FAST: Efficient Robot Action Tokenization.
- Physical Intelligence. Teaching Robots to Listen and Think Harder.
- Physical Intelligence. π0.5: a VLA with Open-World Generalization.
- Physical Intelligence. VLAs that Train Fast, Run Fast, and Generalize Better.
- Physical Intelligence. Real-Time Action Chunking with Large Models.
- Physical Intelligence. π*0.6: a VLA that Learns from Experience.
- Physical Intelligence. Emergence of Human to Robot Transfer in VLAs.
- Physical Intelligence. VLAs with Long and Short-Term Memory.
- Physical Intelligence. Precise Manipulation with Efficient Online RL.
- Physical Intelligence. π0.7: A Steerable Model with Emergent Capabilities.