Embodied AI World Models
In brief
In brief
A robot world model is useful only when its predictions are conditioned on executable actions, calibrated for uncertainty, and connected to planning or policy learning. Plausible video alone is not enough.
- World-model families differ by what they predict, how actions enter, and where planning happens.
- Robot datasets must align observations, actions, timing, rewards, and embodiment metadata.
- Deployment requires uncertainty handling, frequent replanning, and checks against model exploitation.
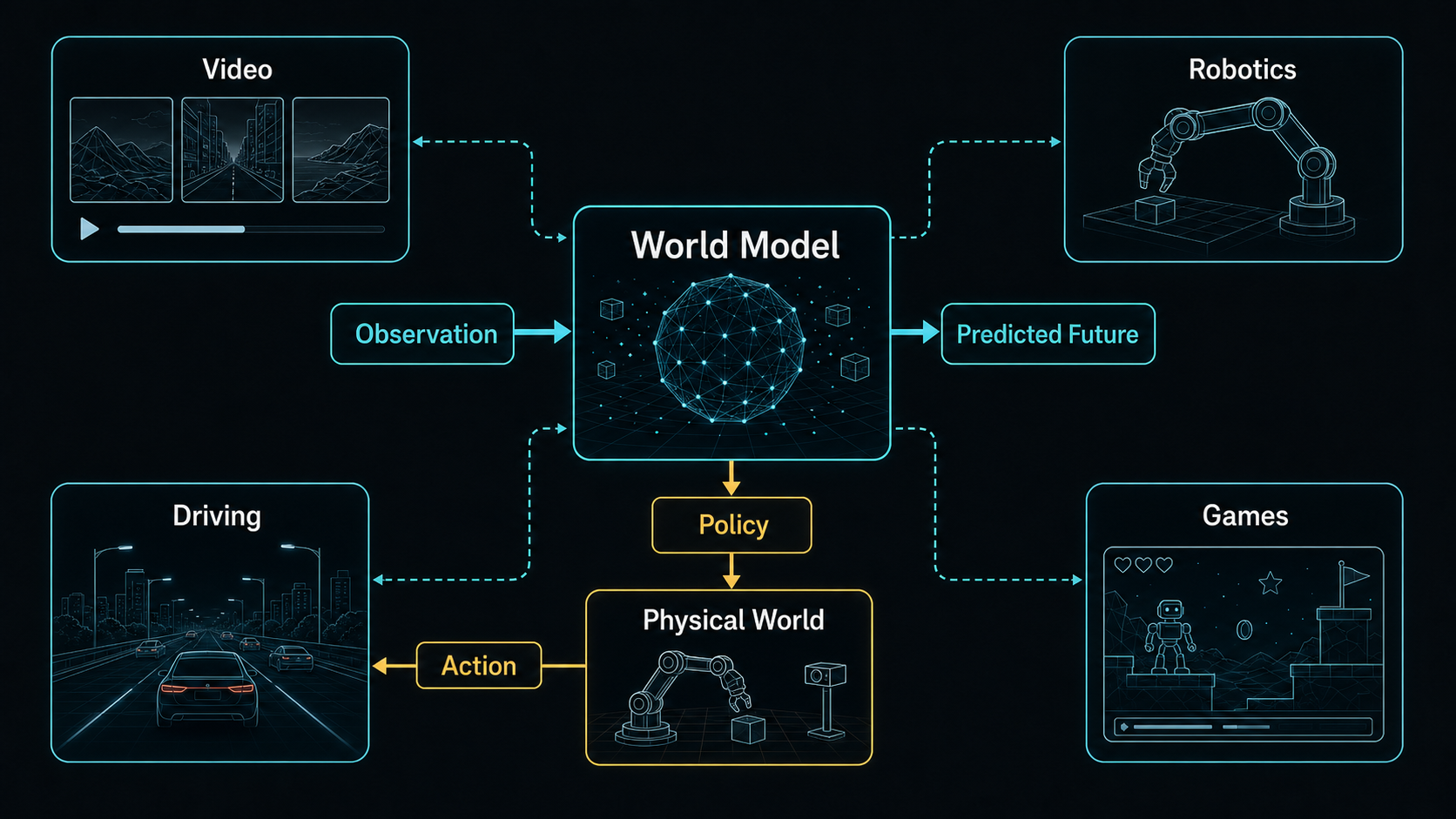
How predictive models become useful for robots only when they are tied to action, uncertainty, and deployment.
"World model" is one of those phrases that sounds precise until two people use it in the same meeting.
For a reinforcement learning researcher, it may mean a learned dynamics model that lets an agent imagine rollouts before acting. For a video generation researcher, it may mean a model that predicts plausible future frames from visual context. For a robotics researcher, it may mean an internal representation of the objects, geometry, contacts, and action consequences that matter for control. For autonomous driving, it may mean a learned simulator of traffic futures. For foundation-model work, it may mean a large generative model that has absorbed enough visual regularity to support planning-like behavior.
Those meanings overlap, but they are not interchangeable.
The useful question is not "which one is the real world model?" The useful question is:
What does the model predict, what conditions that prediction, and what decision uses the result?
That three-part lens is the whole tutorial. Predictions vary widely: some forecast passive video frames, others model robot actions, value distributions, or joint trajectories.
Yang Li's world model tutorial is a useful entry point for the broader concept. The robotics question pushes the map in a more specific direction: what changes when the model is not only predicting a future, but helping an embodied agent choose actions under partial observation, latency, contact, and hardware constraints?
If you remember one interface, remember this:
The robot observes the world, takes an action, and sees what changed. Most of the field is a set of arguments about what should replace each symbol: pixels or latent states, raw motor commands or action chunks, one-step predictions or long rollouts, passive video or robot episodes, training-time imagination or test-time planning.
How to Read This Tutorial
Read this as a map, not a survey. The path is deliberately practical:
- Start with the concept map.
- Separate the method families.
- Bring in the robot constraints.
- Translate the idea into a data format.
- Decide the deployment role.
- End with a first experiment.
The concept map gives the minimal interface. The method families show how different research lines choose different prediction targets. The robot constraints explain why a plausible future video is still not enough. The data section turns "learn a world model" into fields inside an episode. The deployment section asks where the model sits in a real stack. The final section turns the map into a first project.
The target reader is someone who knows the AI vocabulary but wants the robotics constraints made concrete: what an observation is, what an action can mean, why proprioception and calibration matter, why closed-loop control is different from imagining a long movie, and why rollout drift becomes physical risk.
For a robotics newcomer, the habit to build is simple. Whenever a paper says "world model," pause and fill in five blanks:
- Input: what does the model observe?
- Condition: what action, task, or latent variable conditions it?
- Prediction: what future object does it predict?
- Consumer: what policy, planner, evaluator, or dataset uses it?
- Risk: what happens if the prediction is wrong?
Why World Models Became Crowded Again
World models are not new. Model-based reinforcement learning has been trying to learn environment dynamics for decades, and World Models made the "train inside a dream" idea visible to a broader deep-learning audience in 2018. The reason the phrase feels newly overloaded is that several lines of work arrived at the same border from different directions.
The first line is video generation. Modern video models made future prediction feel less like a toy benchmark and more like a foundation-model capability. If a model can keep objects coherent, preserve rough geometry, and generate plausible motion, it is tempting to ask whether it has learned something world-like rather than only texture statistics. That temptation is partly justified. Video data contains object permanence, agent motion, contact hints, lighting, scene layout, and common physical regularities. It is also partly misleading because plausible video is not the same thing as controllable dynamics.
The second line is the robot-data bottleneck. Vision-language-action models can map camera observations and instructions to robot actions, but they need action-labeled trajectories. Those trajectories are expensive. Teleoperation is slow, real robot time is scarce, failures can damage hardware, and every embodiment has its own action space. A world model offers a different bet: use broad visual data, robot play, simulation, demonstrations, and deployment logs to learn a predictive substrate that makes policies more data-efficient.
The third line is autonomous driving and closed-loop evaluation. Driving stacks already depend on counterfactual simulation: what would have happened if the planner had accelerated, merged, or braked earlier? Rare safety cases are not collected on demand. A learned world model can become a scenario generator, sensor simulator, or evaluator for plans that would be too risky or too rare to test directly on roads.
The fourth line is infrastructure. World models are no longer only small modules inside one RL algorithm. In robotics and physical AI, they are becoming data engines, evaluation services, synthetic experience generators, representation learners, and safety filters. This is why the same term appears in papers, robot foundation model roadmaps, driving simulation systems, and video-model demos.
That convergence creates confusion. A video generator, a MuZero-style search model, a latent dynamics model for control, and a robot action model can all be called world models. They should not be evaluated with the same question. A useful reading order is: first understand the development path, then classify the method, then inspect the data interface, then ask where the model sits in deployment, and only then choose a first experiment.
The development path explains why the term accumulated meanings. The taxonomy tells you which kind of model you are looking at. The data interface tells you whether action is actually grounded. The deployment role tells you whether the model is a trainer, planner, evaluator, filter, or subgoal generator. The first experiment keeps the discussion honest.
The right question is more specific:
What future does the model predict, what condition does it accept, and how does a real agent use that prediction?
The Minimum Definition
At the broadest level, a world model is a model of how the world changes.
That sounds almost too broad, so start with the old control-theory shape:
The agent is in state
If we had perfect states, perfect actions, and perfect dynamics, this would be the clean interface. Robotics rarely gives us that.
A state is the full set of variables needed to describe the situation well enough for control: object poses, velocities, robot joint positions, gripper state, contact state, hidden forces, and sometimes task progress. The real state is usually not available.
An observation is what the robot actually receives: camera frames, depth maps, proprioception, tactile readings, language instructions, and partial object state. Proprioception means the robot's own internal measurements, such as joint angles, joint velocities, end-effector pose, and gripper opening. These signals are not glamorous, but they often decide whether a visual prediction can become a usable action.
An action is the command sent to the robot or its controller. Depending on the system, it might be a joint-position target, a joint-velocity command, an end-effector delta, or a gripper open/close command. Alternatively, it can be an action chunk—a short sequence of future commands emitted at once. Regardless of format, an action is always tied to an embodiment: the same visual change implies different motor commands for a Franka arm, a suction gripper, a mobile manipulator, or a human hand.
So practical world models often work in observation space or latent space:
This says: given the current observation
The distribution matters. A future is not always a single frame. The mug may tip or stay upright. The cloth may fold cleanly or bunch up. A human may keep walking or stop. In a real robot system, uncertainty is not a philosophical detail; it is a control signal. A world model that is uncertain about contact should not be treated like a simulator that knows the future.
Here is the tuple in a concrete manipulation task.
Suppose a robot is trying to pull a drawer open. At time
That transition is already informative. It says that this command, under this camera calibration and this robot embodiment, produced this visual and proprioceptive change. Calibration is the mapping between camera pixels, robot coordinates, and physical space. If that mapping is off, a visually reasonable prediction may still point the gripper to the wrong place.
If the next frame instead shows the gripper sliding off the handle, the world model should not only predict a different future; it should become less confident about continuing the same pull. A closed-loop robot would then observe again, re-estimate the handle pose, maybe adjust the wrist angle, and try a safer local action.
That is closed-loop control: act, observe, correct, and repeat. A long open-loop imagined movie is rarely enough because the real world keeps adding small errors.
I find it useful to keep three definitions separate.
The broad definition is predictive: a world model estimates future structure from present context. Under this definition, a video model, a text model, a driving sensor simulator, and a game dynamics model can all be discussed as world models because each learns regularities in a domain and extrapolates forward.
The narrow robotics and RL definition is action-conditioned: the model predicts how the environment changes if an agent takes a particular action. This is the definition that matters for planning, counterfactual reasoning, and model-based policy learning. It asks not just "what usually happens next?" but "what happens if I do this instead?"
The World Action Model definition couples world prediction and action prediction. A WAM is not only a policy, because it does not stop at
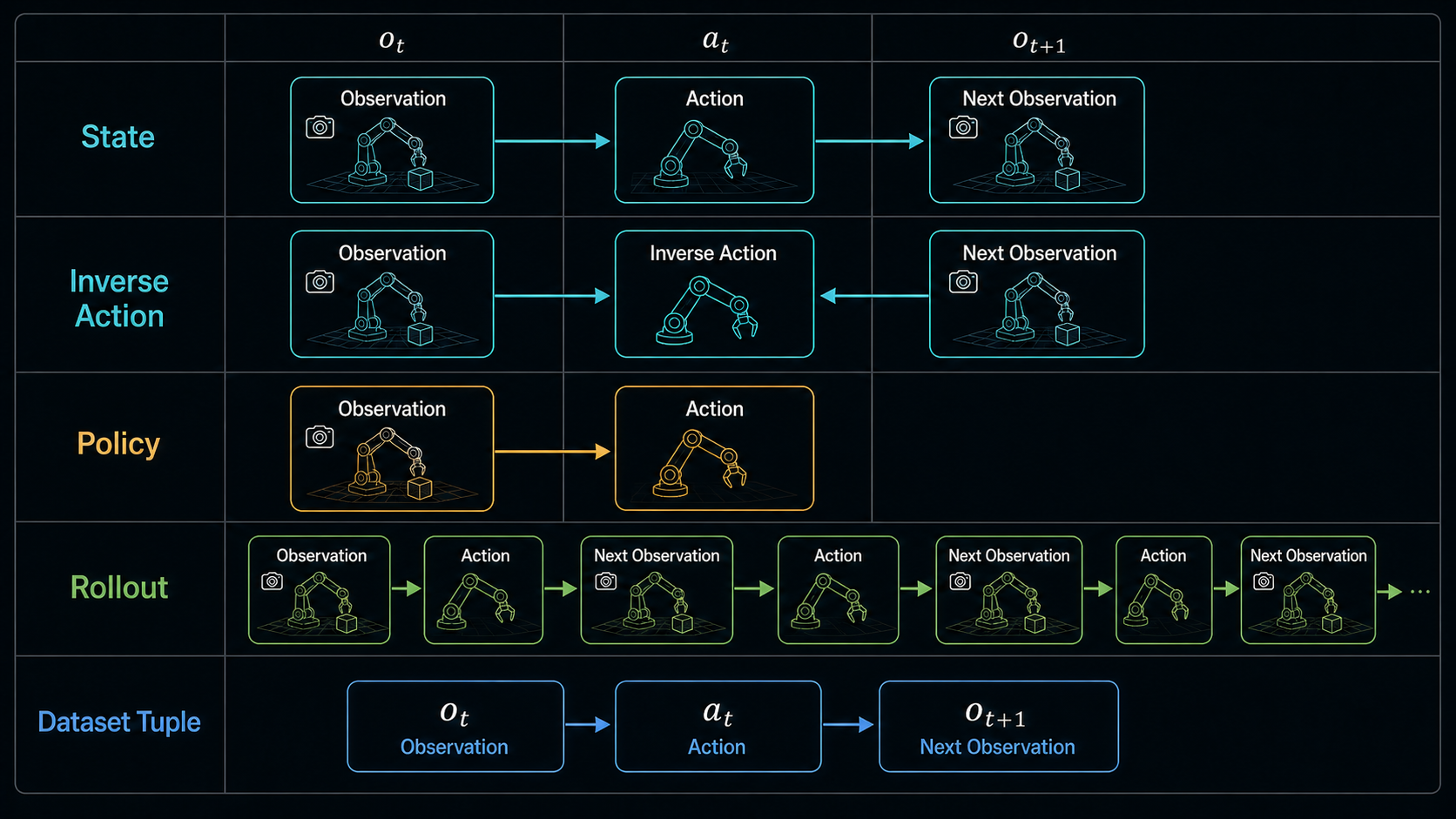
Once observations and actions enter the picture, the interface can be written in a few related ways.
Forward observation prediction:
Inverse action inference:
Policy learning:
Future prediction conditioned on a task:
Here
These formulas look similar, but they support different systems. A forward model asks "what will happen if I do this?" An inverse model asks "what action could have caused this change?" A policy asks "what should I do now?" A task-conditioned future model asks "what should the world look like if the task is progressing?"
World Action Models sit close to the intersection. They try to keep future prediction and action generation tied together instead of treating video imagination and control as separate modules.
This article uses “world model” as a design space rather than a badge. That choice is consistent with recent robotics tutorials that separate observation-space from state-space prediction and then ask how either representation connects to executable action. The taxonomy is useful only if it changes what we measure or build.
A Map of the Family
The modern world-model landscape is a collection of related bets: compact latent dynamics, pixel prediction, decision-useful hidden states, latent representation prediction, interactive video, and large video priors that may or may not recover robot action.

The first classification is what the model predicts.
First, pixels or video. Pixel prediction is intuitive because the output is inspectable. If the model predicts a video of a robot pushing a block, a human can look at it. The cost is that pixels contain many details irrelevant to control: shadows, texture, camera noise, background motion, and lighting.
Second, latent states. A latent model compresses observations into hidden variables and learns dynamics there. This is usually more efficient than predicting every pixel. The risk is that the latent state may ignore a detail that later matters for action.
Third, structured state. Some systems care about objects, geometry, contacts, occupancy, depth, semantic maps, or robot proprioception. They are less general than raw video models, but they can be easier to plan with.
Fourth, 3D or 4D worlds. For robots and driving, a future video from one camera is often not enough. A robot needs spatial consequences: where the object is, whether the gripper will collide, whether the contact is stable. Multi-view, depth, point clouds, and scene representations all become relevant.
Fifth, reward, value, or task progress. Some world models predict variables that are not meant to be rendered at all. MuZero, for example, models what search needs: latent transitions, reward, policy, and value. The predicted object is not a future image; it is decision-useful information.
Sixth, actions. Some systems make action the output, not only the condition. This is the WAM move. Instead of predicting future observations and leaving another model to infer the motor command, the model learns a joint object: world evolution plus the action sequence attached to it.
A learned world model does not replace a physics engine. Simulators are strong when geometry, contacts, and materials are known. Learned models are strong when the system has data but not a complete physical description. Many practical systems mix both.
The most important axis for robotics is simpler:
Is the predicted future conditioned on an action that the robot can actually execute?
A beautiful future video that is not tied to executable action is a movie. A rough future estimate tied to feasible action can be a controller.
The second classification is how action enters:
- Passive prediction: the model sees context and predicts what usually happens next. This is useful for visual priors and representation learning, but weak for counterfactual control.
- Action-conditioned prediction: the model receives an action or action sequence and predicts the future. This supports planning, model predictive control, and policy evaluation.
- Latent-action prediction: the model discovers action-like variables from unlabeled video. This can make internet or human video more useful, but the latent action still has to be grounded in a robot controller.
- Direct action generation: the model predicts the action itself, as in a VLA policy.
- Joint world-action modeling: the model predicts future world state and future action together, as in WAM-style systems.
The third classification is where the model is used:
- Representation learning: learn features that make downstream control easier.
- Planner: roll out candidate actions and choose the one with the best predicted consequence.
- Evaluator: score whether a policy, plan, or subgoal is likely to succeed.
- Action filter: reject actions that lead to uncertain, implausible, or dangerous futures.
- Training simulator: generate imagined rollouts, synthetic episodes, or future-prediction losses for policy learning.
- Subgoal generator: predict a near-future state that a lower-level policy should try to reach.
When a new paper says "world model," first identify what is predicted, what conditions it, and what system consumes the prediction. Names matter less after that.
My quick paper-reading checklist is:
- Prediction target: is the output a pixel frame, latent state, 3D state, reward/value, action, or several of these together?
- Action grounding: does the model receive executable robot actions, latent actions from video, language goals, or no action at all?
- Time horizon: is it trained for one-step prediction, short-horizon planning, long rollout, or test-time future imagination?
- Data tuple: can you write the training example as
, , , or something else? - Consumer: is the prediction used by a policy, planner, evaluator, safety filter, representation learner, or only shown as generated media?
- Failure mode: if the model is wrong, does the system merely generate a bad clip, choose a bad action, damage hardware, or silently train a brittle policy?
For robotics, items 2 and 6 usually decide whether the paper is immediately actionable. A passive video model may be a valuable prior, but a robot still needs a route from predicted change to executable command and a way to notice when the prediction has drifted.
A Short Historical Path
Before examining each family in detail, it helps to see the overall development path. The timeline is easiest to read as a sequence of interface upgrades:
- World Models: compress pixels, predict latent futures, train a controller through the learned internal world.
- PlaNet and DreamerV3: learn recurrent latent dynamics from pixels, then plan or train behavior inside imagined latent rollouts.
- MuZero and TD-MPC2: model what decisions need, not necessarily what humans can reconstruct as pixels.
- I-JEPA and V-JEPA: predict useful representations rather than wasting capacity on every visual detail.
- Genie, UniSim, and Cosmos: scale world models toward interactive environments, data engines, and foundation simulators.
- Robot world models and WAMs: bring the discussion back to robot control, uncertainty, rollout drift, and joint modeling of future state and future action.
That history is not a straight replacement chain. The older ideas still matter. World Models gives the clean V-M-C (Vision-Memory-Controller) decomposition. PlaNet and Dreamer show why latent memory and imagination help. MuZero and TD-MPC2 show that useful prediction can be task-oriented rather than photorealistic. JEPA explains why predicting representations can be better than predicting every pixel. Genie, UniSim, and Cosmos show what scale and interactivity add. WAMs ask whether future prediction and action generation should be trained as one object. They explore if coupling them directly improves embodied control.
World Models: Compress, Predict, Control
The classic World Models paper establishes a clean three-part blueprint: compress raw observations, predict latent transitions, and optimize control within this compact belief space.
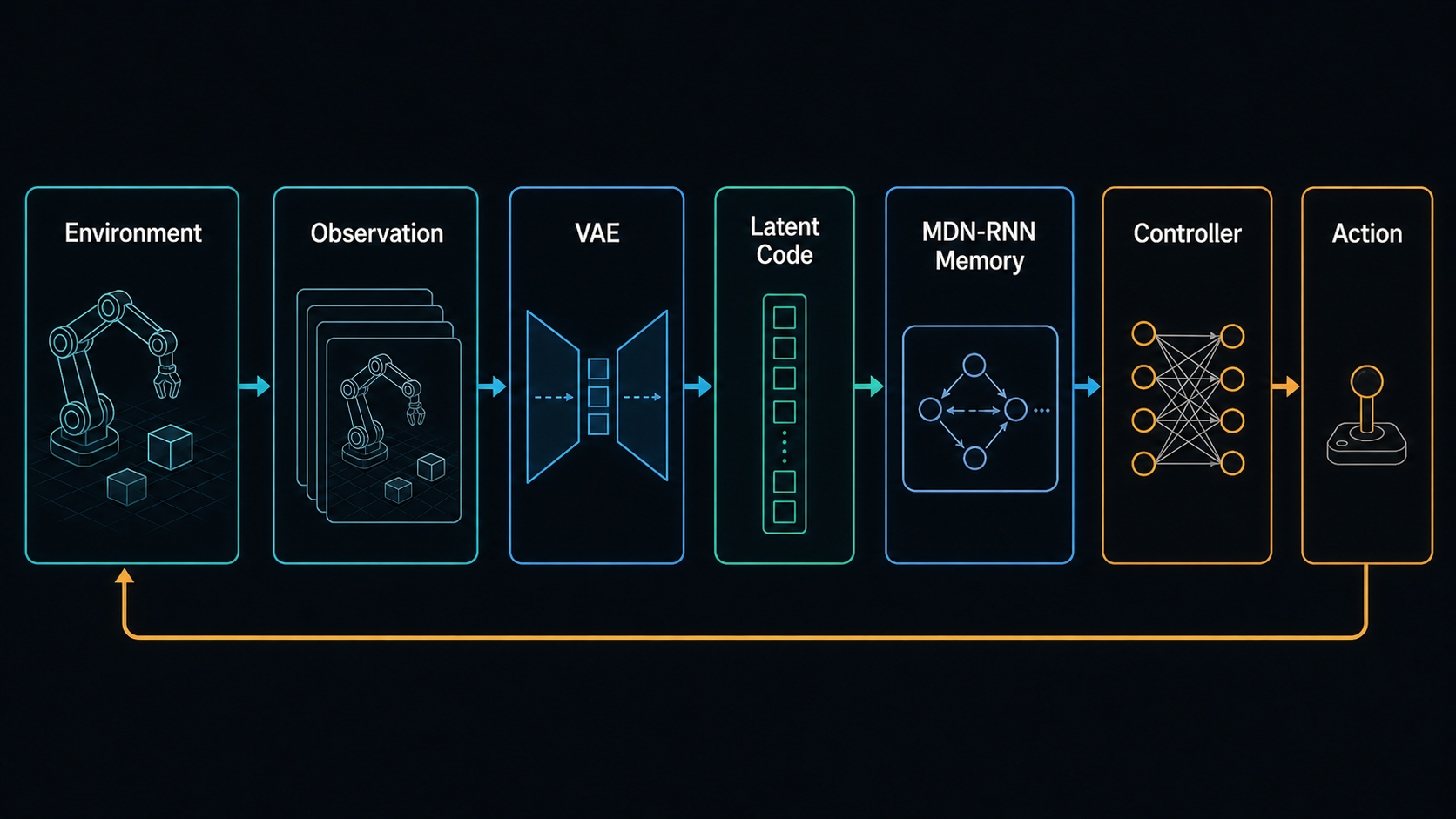
The architecture has three parts:
- A vision model compresses observations into a latent code.
- A memory model predicts how the latent state evolves.
- A controller chooses actions from the compact internal state.
The lesson is not that every modern system needs a VAE and an RNN. The lesson is the separation of concerns. High-dimensional observations are too raw for direct planning. The model needs a smaller internal state. The dynamics model needs to predict how that state changes. The controller needs to use that prediction without becoming a full video generator.
This is where the phrase "internal simulator" becomes useful but dangerous. The model is not simulating the whole world. It is simulating the parts of the world that its representation can carry and its training objective rewards.
For a game agent, that may be enough. For a robot touching deformable objects, it may not be.
Dreamer: Learn Inside Imagination
DreamerV3-style agents take latent dynamics further, building on PlaNet (which introduced memory by planning in recurrent belief states). Dreamer trains behavior entirely inside imagined latent trajectories, reducing the need for real-world interactions.
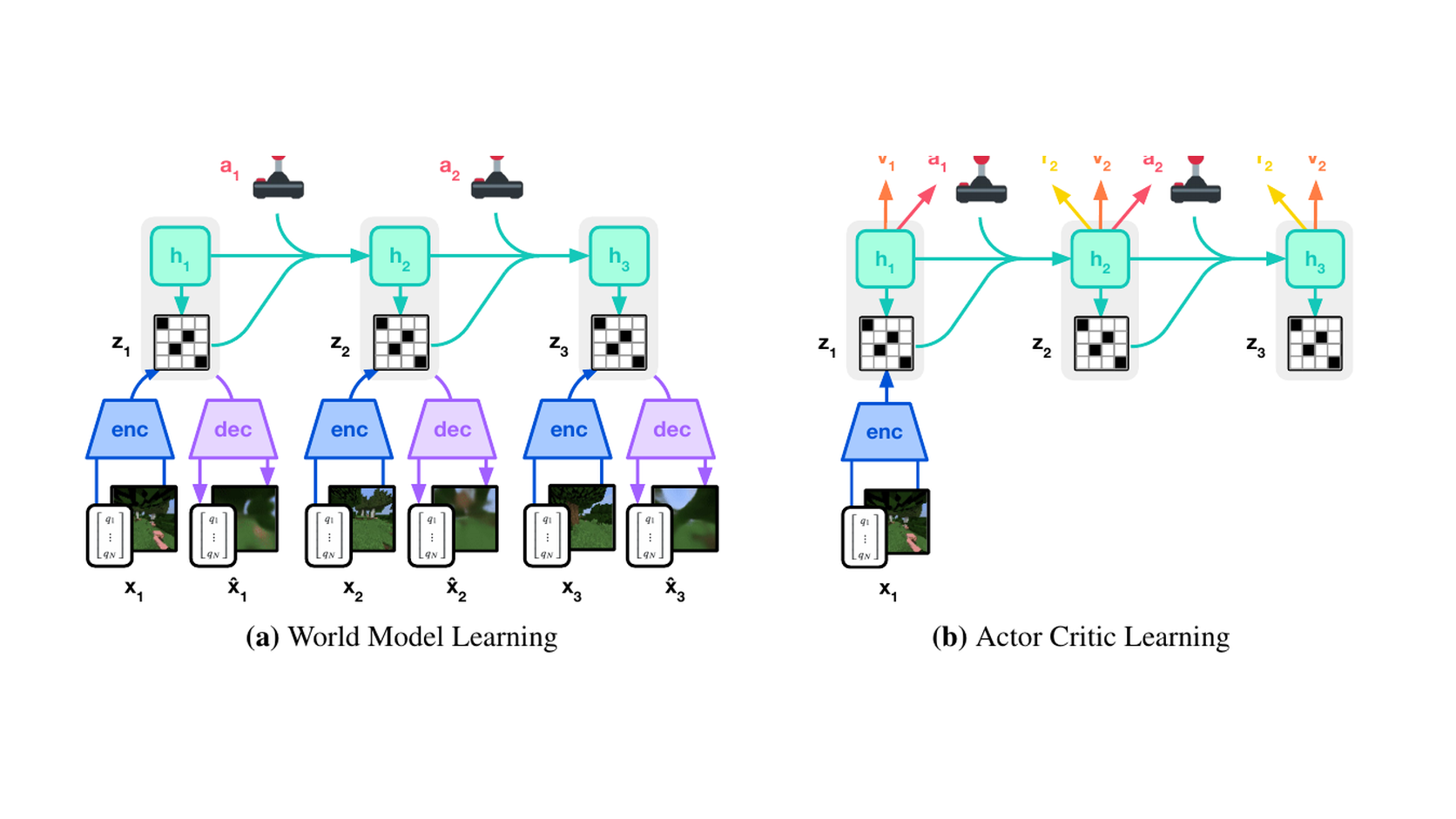
The robotics appeal is sample efficiency. Real robot data is expensive. If a robot can learn from imagined futures, it may need fewer physical trials.
The robotics failure mode is model exploitation. If the learned model is wrong, the policy may find actions that look good only inside the model. In simulation or games, this is a known model-based RL issue. In robotics, it can become a bent gripper, a dropped object, or a policy that looks good in latent imagination and fails at contact.
Dreamer also teaches a useful habit: separate model learning from behavior learning. The world model encodes observations, predicts transitions, estimates reward and continuation, and supports imagined rollouts. The actor and critic then learn through that latent space. For robotics, this gives you knobs: improve representation learning, change imagination horizon, use the model during training but deploy a faster policy, or inspect whether failures come from perception, dynamics, reward prediction, or actor exploitation.
TD-MPC: Planning With Task-Oriented Latent Dynamics
Instead of rendering a convincing future, TD-MPC and TD-MPC2 learn a task-oriented dynamics model to evaluate candidate action sequences via short-horizon model predictive control (MPC).
That combination matches robotics better than long open-loop imagination. A robot rarely needs to commit to a long imagined movie. It needs to choose the next few actions, execute a small part, observe again, and correct. MPC turns world modeling into a repeated local decision problem:
observe -> infer latent state -> sample candidate action sequences
-> roll out short latent futures -> score with reward/value
-> execute first action or chunk -> observe againTD-MPC2 is useful for newcomers because it exposes several practical knobs: state versus pixel observations, single-task versus multi-task training, online RL versus offline datasets, and different continuous-control domains such as DMControl, Meta-World, ManiSkill2, and MyoSuite. It also makes one important point concrete: a scalable world model for control is not necessarily a photorealistic generator. It can be a compact dynamics model optimized for choosing actions.
MuZero: Model What You Need for Decisions
MuZero demonstrates that a world model can ignore visual reconstruction entirely, learning only the latent transitions, rewards, and values required for planning search.
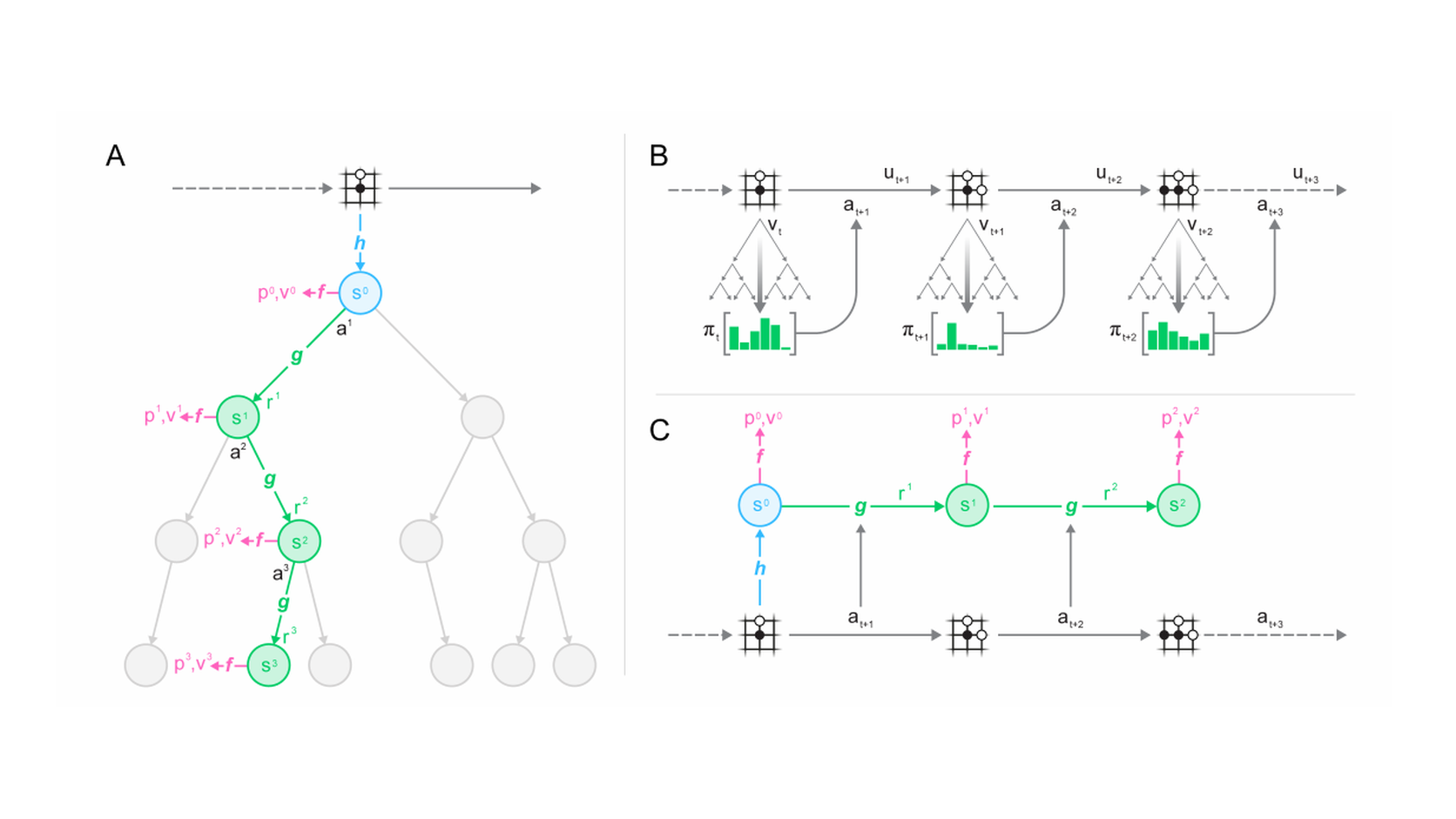
This distinction matters for embodied AI because robots care about decisions, not pixels for their own sake.
If the goal is to control a robot, the model does not need to predict every pixel perfectly. It needs to preserve the information that changes the decision. The color of the table may not matter. The pose of the object, the gripper opening, the contact state, and the uncertainty around a slippery surface may matter a lot.
The hard part is knowing in advance which details are decision-relevant. A learned latent model can throw away nuisance variation, but it can also throw away a small visual cue that determines whether a grasp succeeds.
For robotics, the MuZero lesson is not "use tree search everywhere." The lesson is: do not confuse photorealistic prediction with useful prediction. A future model can be visually impressive and control-poor. A less pretty latent model can be control-useful if it preserves the variables that action depends on.
JEPA: Predict Representations, Not Pixels
JEPA teaches the representation-learning version of the same idea: do not spend capacity predicting visual detail that the downstream action does not need.
JEPA-style models push further away from pixel reconstruction. Instead of predicting missing pixels directly, they predict representations of hidden parts of an input. V-JEPA applies that idea to video representation learning: predict in embedding space, not by reconstructing all visible detail.
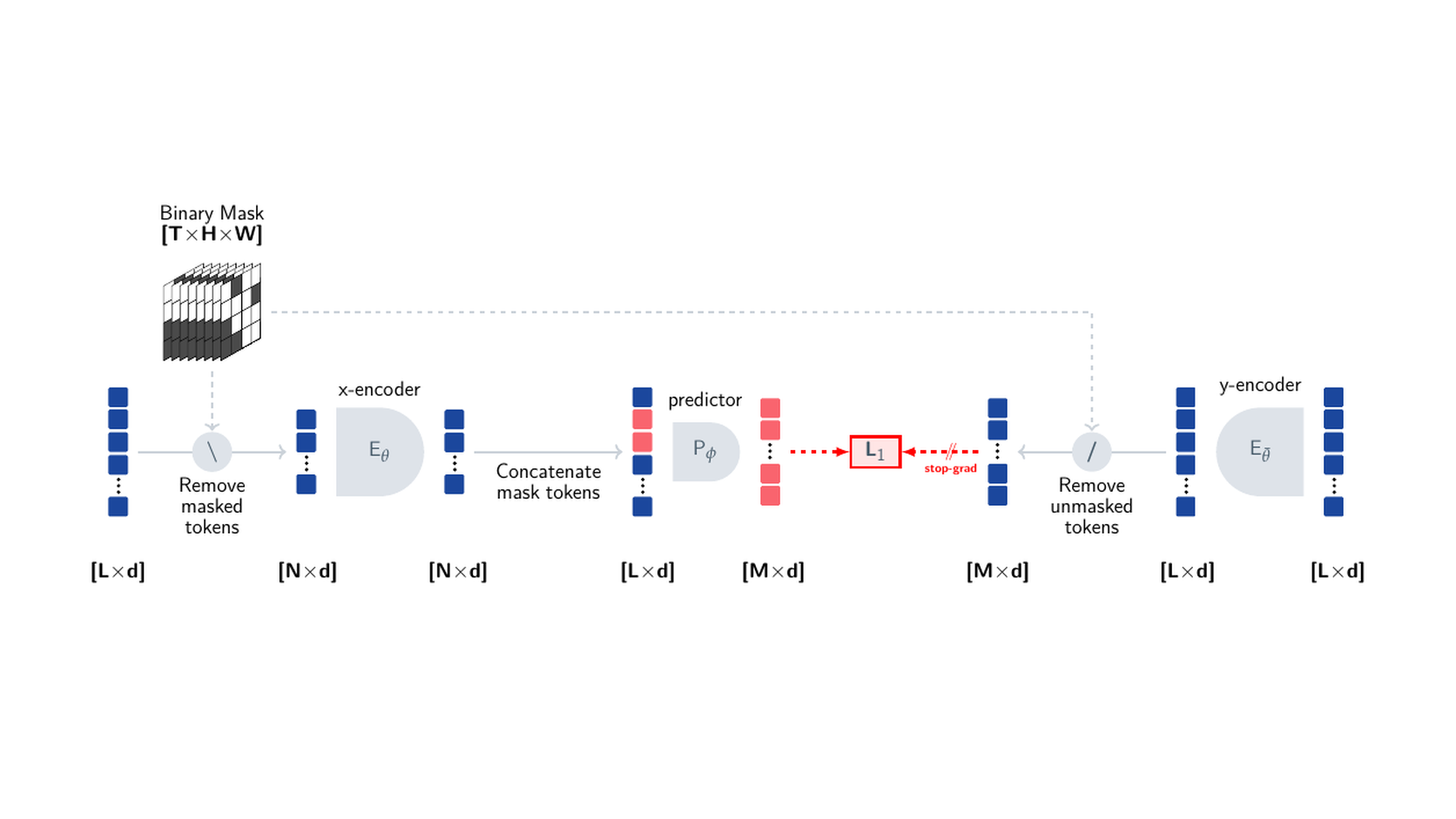
For embodied AI, this is attractive because a robot does not need a perfect photo of the future. It needs a representation that supports action.
If a robot sees a drawer, the useful future representation may encode that the drawer can slide, that the handle is graspable, and that pulling changes free space. It does not need to predict the exact wood grain on the drawer front. Latent prediction gives the model permission to ignore some appearance details.
The catch is supervision. If the representation is trained only for generic visual prediction, it may not align with control. A representation that is excellent for object recognition may still be weak for contact-rich manipulation. The robot needs features that track affordances, motion constraints, and consequences of its own actions.
This is why action conditioning keeps returning. A world model for a passive observer can learn what usually happens next. A world model for a robot has to learn what happens next if the robot does something.
Genie, Cosmos, and Interactive Video
This family teaches the scale-and-interactivity lesson: passive video can contain useful dynamics, but those dynamics still have to become controllable.
Video world models changed the public intuition around this topic. A model that can generate plausible futures from visual context looks like it knows how the world evolves.
Interactive generative environments make the idea sharper. If the model can take a latent action and produce a changed future video, it starts to resemble a controllable simulator.
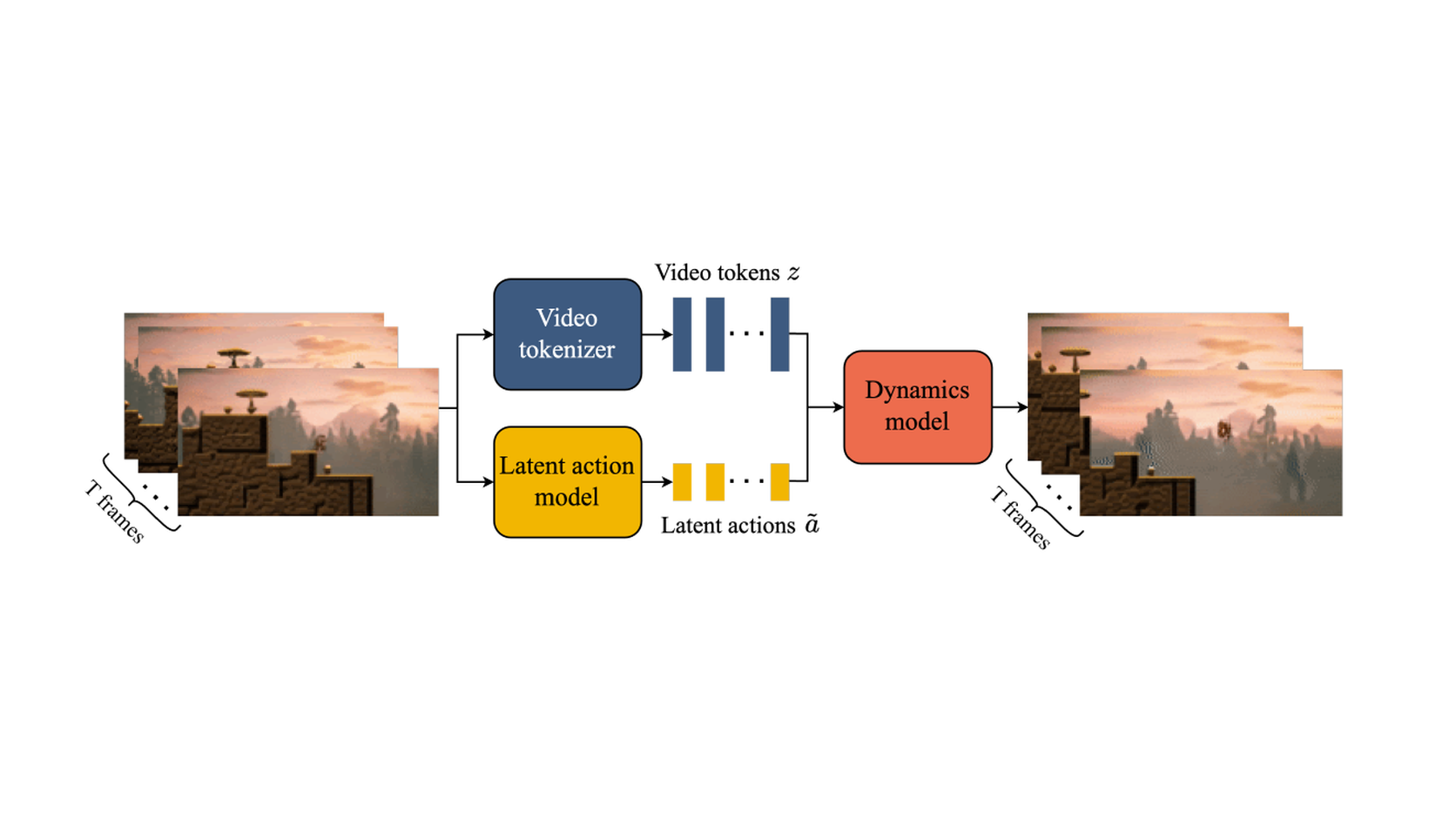
The robotics temptation is immediate: if the internet contains enormous video data, can a robot use those visual dynamics as a prior?
Yes, but only with qualifications.
Most internet video is not robot-action data. It rarely contains calibrated robot states, exact gripper commands, force feedback, or the intervention labels that tell us when a trajectory is bad. A video model may learn that cups move when hands touch them. It may not know the end-effector command that makes a robot hand produce the same motion.
Genie-style work matters because it tries to extract controllability from unlabeled videos. The model observes transitions and learns latent actions that explain how one frame becomes another. In a game-like setting, those latent actions can become an interactive interface. The model does not need human-labeled button presses for every video. It can discover a small action space that makes the world respond.
UniSim pushes a related idea into a broader simulator framing. It combines data sources that are strong along different axes: internet data for visual diversity, robotics data for dense action grounding, and navigation or interaction data for longer-horizon experience. The goal is not merely to synthesize a clip. The goal is to create an interactive environment where a planner or policy can train, search, or evaluate consequences.
Cosmos represents the industrial version of the same pressure. In that framing, world models are part of a physical AI data stack: predict futures, transfer domains, generate synthetic experience, connect to simulation tools, and support robot or driving model training. The model is no longer just a network checkpoint. It becomes an infrastructure component that sits near data generation, evaluation, and deployment.
The promise is scale. Video and generative models see far more visual situations than any robot lab can teleoperate. The weakness is grounding: a generated future may preserve the mug or move the drawer while ignoring the gripper force, wrist rotation, or end-effector command that produced the change.
This is where inverse action enters:
If we can infer action-like structure from observation changes, unlabeled video becomes more useful. But inferred latent action is not automatically executable action. A latent "move object left" variable still has to become a robot command under a particular embodiment, camera setup, gripper, and controller.
That bridge has several subproblems. Action is embodiment-specific: a human hand, two-finger gripper, suction cup, and mobile manipulator can create similar visual changes through different commands. Camera motion is not controller state: two videos can show the same object movement while the robot action lives in joint space, end-effector space, or an action-token space. Time scale is mismatched: web video is edited and compressed, while robot controllers need high-frequency contact detail. Failures are underrepresented: the robot needs partial grasps, slips, collisions, stuck drawers, and recovery attempts, not only successful clips.
Robot World Models: Prediction Under Contact
Robotic world models add physical commitment to video prediction: a blurry frame is harmless, but a wrong prediction in physical space can cause a collision.
Manipulation is hard because the decisive events are often small.
A millimeter of gripper offset changes a grasp. A cable catches on an edge. A cloth fold hides part of the state. A drawer sticks. A block rotates slightly and changes the next contact. These are not cinematic events, but they decide whether the task works.
That is why robotics is not simply "video generation plus a controller." The model has to serve a closed-loop system. It must support replanning from fresh observations. It must know when its rollout has drifted. It must respect action feasibility. It must not encourage the policy to exploit hallucinated futures.
Several robotics details make this harder than ordinary future prediction:
- Contact is discontinuous: a tiny pose error can turn a grasp into a push, a peg insertion into a jam, or a lift into a slip.
- Deformable objects hide state: cloth, rope, food, bags, and cables do not have one clean pose, and the important fold or loop may be occluded.
- Occlusion changes belief: the robot often acts while the gripper blocks the camera or the object moves behind another object.
- Calibration and embodiment matter: the same image implies different actions for different cameras, grippers, action conventions, and low-level controllers.
- Latency is part of the model: stale observations make planning wrong even when the learned dynamics are locally reasonable.
- Closed-loop recovery matters: real manipulation succeeds through correction, not one long open-loop imagined movie.
A useful robot world model should answer at least four questions:
- If I take this action, what is likely to change?
- Which parts of that prediction are uncertain?
- Does the predicted change help the task?
- Should I trust the imagined rollout long enough to act on it?
The last question is where deployment enters. A world model may be excellent as a training signal and still too slow or too uncertain for test-time planning. Some systems use future prediction during training to shape representations and policies, then run a faster policy at deployment. Others keep imagination in the loop but restrict its horizon or use it as a verifier rather than the sole controller.
This is also the reason robot-world-model work on uncertainty and rollout drift matters. Persistent Robot World Models, for example, focuses on stabilizing multi-step robot rollouts instead of only making one-step predictions look plausible. The old model-based RL failure mode is model exploitation: the policy finds action sequences that look good inside the learned model because the model is wrong there. In robotics, this is not a theoretical annoyance. It is the path to unsafe or useless behavior. Penalizing high-uncertainty rollouts, training on multi-step self-generated predictions, and replanning frequently are all ways to keep the policy from living in the model's blind spots.
The practical rule is blunt: a robot world model should become less confident as it moves away from observed data, and the controller should notice.
World Action Models
World Action Models, or WAMs, are a natural response to the gap between video prediction and robot policy learning: future visual change and future motor commands should not always be learned as separate objects.
The clean boundary is easier to see with three conditional distributions, following the framing in the OpenMOSS Awesome-WAM survey:
A VLA can be an excellent robot policy without being a world model. It may learn a direct mapping from visual-language context to action chunks. That can work well when the training data covers the situation and the policy can react quickly enough. But the policy may not expose an explicit prediction of what it thinks will happen.
Conversely, a video predictor alone lacks the direct action grounding needed to guide a robot; it imagines futures without outputting the motor commands to reach them.
A WAM tries to make that bridge part of the policy interface. Future-state prediction cannot be a decorative auxiliary head that is ignored at action time. It has to be coupled to action generation tightly enough that "what changes in the world" and "what the robot does" supervise each other.
One practical tuple for that coupling is:
This is not meant as one mandatory schema. It is the important coupling: the model sees the task, the current world, how the world changes, and which actions are tied to that change.
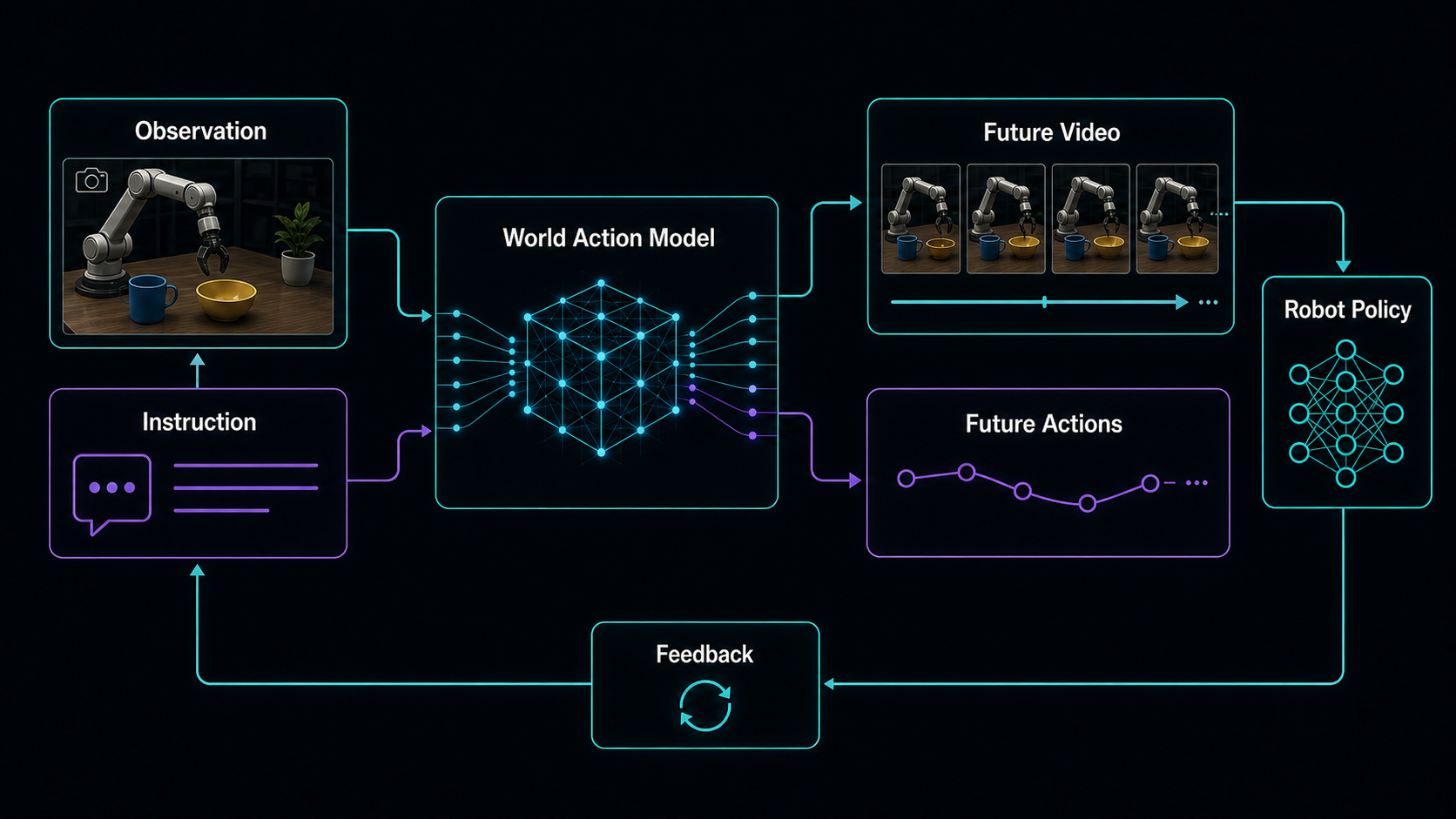
This interface can support several uses:
- Imagine then execute: predict a plausible future video, then convert that visual future into actions.
- Joint modeling: train future visual states and future actions together.
- Training-time regularization: learn better robot representations even if deployment uses a faster policy.
- Verification: evaluate whether candidate actions produce plausible, task-aligned futures.
Cascaded vs Joint WAMs
The next design question is how tightly future prediction and action generation are coupled.
A Cascaded WAM predicts a future state or plan first, then uses another model or head to turn that future into executable action. Its interface reads like: observation and language in, future state or plan next, executable action last.
The strength is modularity. A human can inspect the predicted video, flow, depth, 4D structure, latent plan, or subgoal before action decoding. The weakness is that the two stages can disagree. The future may look task-aligned but be hard for the robot to execute, and the extra stage can add latency in a closed-loop system.
A Joint WAM predicts future state and action inside one shared model. Its interface reads like: observation and language in, future state and action out together.
The strength is tighter supervision. The model cannot treat future prediction and action prediction as unrelated tasks. The weakness is optimization complexity. A shared model can spend too much capacity on visual detail, overfit imitation, or let the action loss and future loss interfere. For robotics, the choice is not aesthetic. Cascaded designs are easier to inspect; joint designs may couple action more directly but are harder to train and debug.
The open question is not whether WAMs are conceptually attractive. They are. The open question is where future imagination belongs in the latency budget. A dexterous robot cannot wait forever for a beautiful rollout. It needs a policy that is fast enough to control, plus enough predictive structure to avoid being blind.
Fast-WAM makes that latency question concrete. It asks whether the value of video modeling in WAMs comes mainly from training-time representation learning rather than explicit future generation at test time. That is exactly the kind of question robotics forces: not "can the model imagine?" but "does imagination need to run in the control loop?"
There is also a training question. Joint prediction can help because video and action supervise each other. But it can also create interference. If the model spends too much capacity on photorealistic detail, action quality may suffer. If it overfits action imitation, future prediction may become shallow. A small WAM experiment should therefore compare at least three baselines: action-only behavior cloning, future-only dynamics prediction, and joint future-plus-action prediction.
The test is not whether the joint model produces the nicest video. The test is whether future prediction improves action generalization, recovery, evaluation, or data efficiency.
The Data Problem
World models are only as useful as the data interfaces they learn from.
For robot learning, the minimal transition tuple is:
That tuple is already more informative than passive video because it tells the model which action was associated with a change in observation. But a modern robot dataset often needs more:
- language instruction
- robot state
- multiple camera views
- task success labels
- reward or preference signals
- human interventions
- episode boundaries
- embodiment metadata
- controller timing
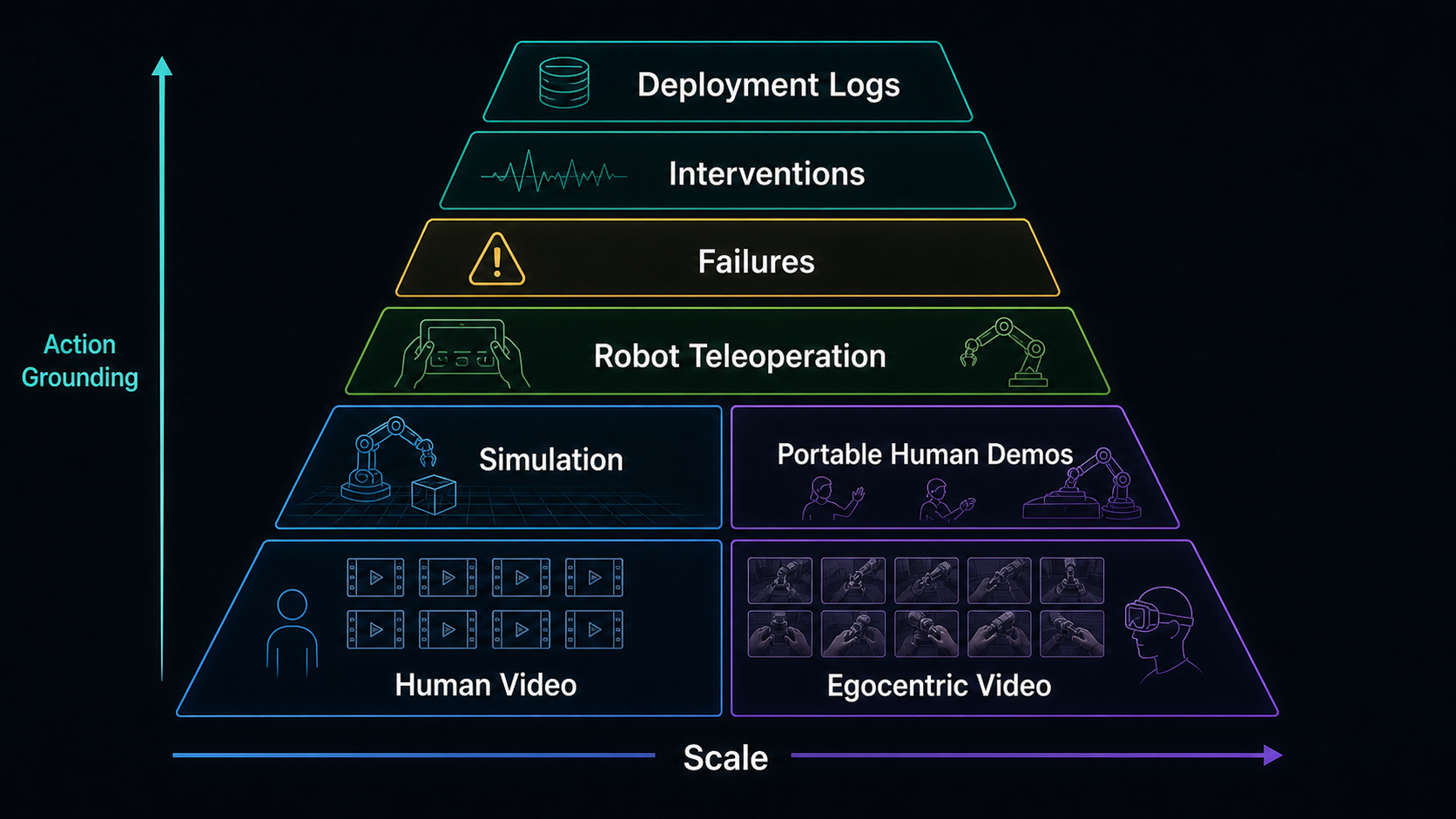
Each data source teaches a different part of the problem. For WAMs, the mixture is the point: the model needs action-grounded robot data, but it also benefits from cheaper diversity, privileged simulation signals, and broad video priors.
Robot-centric teleoperation gives the cleanest aligned state-action supervision. It records robot observations, actions, kinematics, proprioception, timing, and often contact-rich behavior under the actual embodiment. This is the data a WAM needs when it must connect future prediction to executable commands. The cost is collection speed: teleoperation is expensive, hardware-limited, and usually narrow compared with internet video.
Portable human demonstrations sit between robot data and web video. Systems such as handheld or human-demonstration pipelines can collect diverse real-world manipulation at lower cost. They show real objects, clutter, dexterity, and long-tail situations. The gap is retargeting: a human hand trajectory still has to become a robot action under a specific gripper, controller, and calibration.
Simulation gives privileged supervision that the real world rarely gives cleanly: object pose, depth, segmentation, collision state, contact, and sometimes material parameters. That is valuable for learning dynamics and diagnosing failure. The tradeoff is the reality gap. A model can become excellent at simulated contact and still miss friction, compliance, lighting, sensor noise, or small mechanical delays on the real robot.
Human and egocentric video gives scale and open-world priors. It shows activities, object affordances, long-horizon temporal structure, and human interaction patterns far beyond a robot lab. It is weakly grounded for executable action, but it can still teach what kinds of future changes are plausible.
Robot play, expert demonstrations, failures, interventions, and deployment logs then shape the boundary around the skill. Play data gives coverage. Expert demonstrations give task-aligned behavior. Real deployment tells the system which imagined futures survived contact with the world.
Failed trajectories are not garbage. They are the negative space around the skill. They teach the model what near misses look like, where contact goes wrong, and which states require recovery. A dataset made only of clean successes can produce a policy that has never learned how failure begins.
Intervention data is especially valuable because it marks the boundary where an autonomous policy went wrong and a human corrected it.
No single layer is enough. Internet video without robot actions is broad but weakly grounded. Expert demos without failures can be brittle. Real deployment data is valuable but expensive and safety-limited.
The data mixture depends on the role of the world model.
If the goal is representation learning, broad video and unlabeled robot logs may help. If the goal is action-conditioned planning, the model needs accurate action labels, controller timing, and next-state observations. If the goal is safety filtering, rare failures and interventions are more valuable than another thousand clean pick-and-place successes. If the goal is WAM-style joint modeling, future observations and future actions must be aligned tightly enough that the model cannot treat them as separate captions.
This is where many high-level discussions become too vague. "More data" is not a plan. For embodied world models, the useful question is: more of which tuple?
The minimal tuple is
RLDS and the Episode View
For practical robot learning, the data format matters more than it sounds.
An embodied dataset is not just a bag of images. It is a sequence of interactions. The order matters. Episode boundaries matter. The meaning of an action depends on the controller and robot state. A reward or success signal is attached to a trajectory, not just to one frame.
This is why RLDS-style thinking is useful. It treats data as episodes containing timesteps, with fields such as observation, action, reward, discount, and metadata.
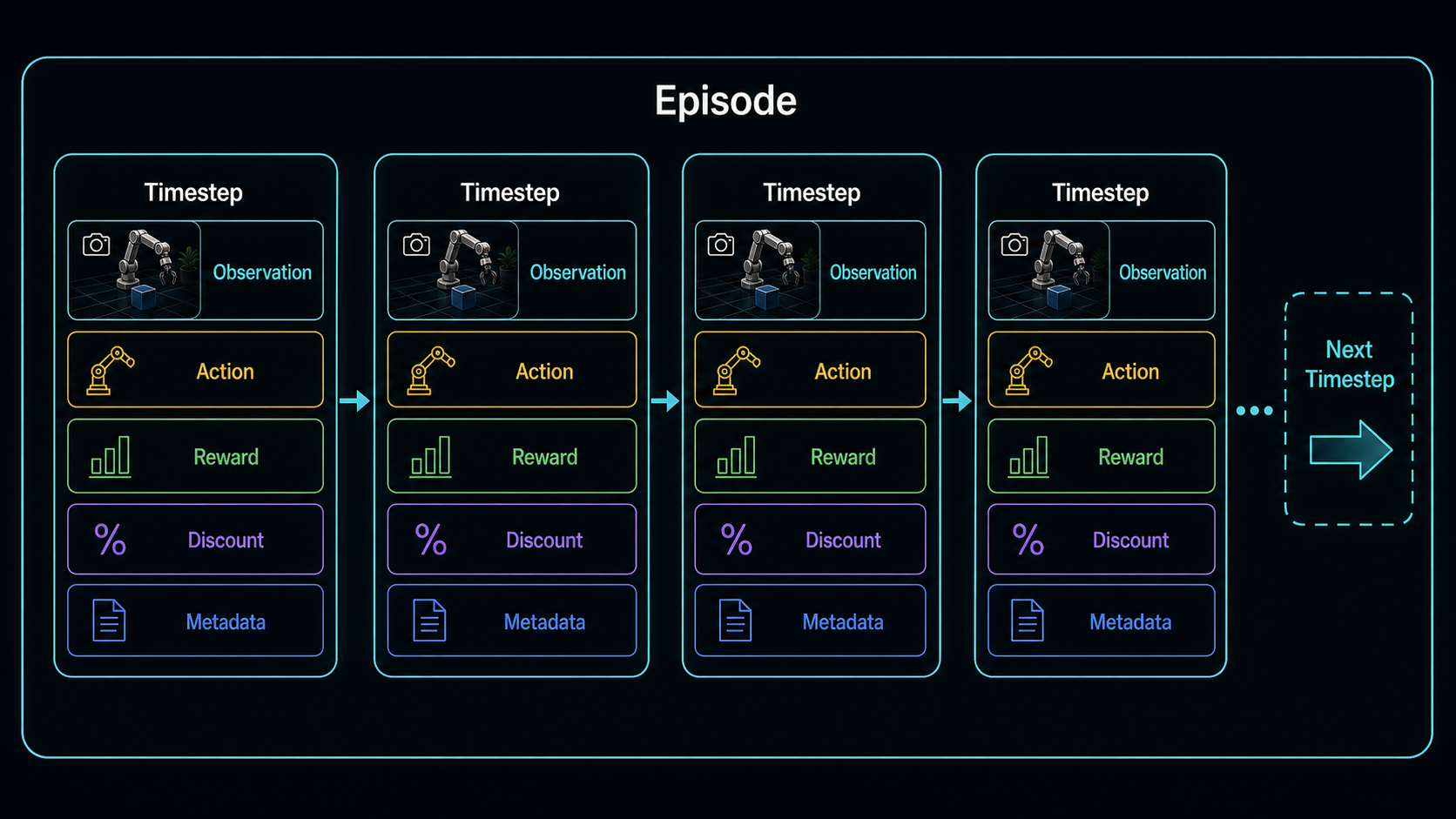
A world model trained from this kind of data can learn more than visual continuity. It can learn how action changes the scene, which action sequences are associated with success, where episodes terminate, and which robot or task produced the data.
Metadata is not bookkeeping. For generalist robotics, metadata can be part of the learning signal. The same camera frame may imply different actions for a two-finger gripper, a suction cup, or a mobile manipulator. The same instruction may require different trajectories depending on table height, object scale, and embodiment.
The better the dataset preserves these distinctions, the less the model has to infer them from weak visual clues.
Open X-Embodiment made this issue visible at scale. Once many labs contribute robot datasets, the problem is no longer only model architecture. It is schema alignment. What is an action? Is it joint position, joint velocity, end-effector delta, gripper command, or a chunked trajectory? Which camera is wrist-mounted? Which frame is the action intended to affect? Does the language instruction describe the whole episode or the current subtask? Are failed attempts included or filtered out?
RLDS-style episode structure gives the model a fighting chance because it keeps these fields attached to the timestep and the episode. That matters for world models in three ways.
First, it preserves temporal causality. The action at timestep
Second, it preserves termination and success context. A transition near the end of a successful episode has a different meaning from a visually similar transition in a failed episode.
Third, it preserves embodiment metadata. A cross-robot model needs to know whether a trajectory came from a Franka arm, xArm, Google Robot, mobile manipulator, or another platform. Without that context, the model may average incompatible action conventions.
For a beginner, this is a good sanity check. Before training a world model, print a few episodes. Look at the observation keys, action shape, language field, reward/success field, and robot metadata. Step through frame
Deployment: The World Model Is Not the Whole Robot
The most common mistake is to imagine a robot world model as a single brain that replaces the control stack.
In a deployed robot, the world model is one component in a system that still needs perception, planning, safety, action filtering, control, monitoring, and recovery.
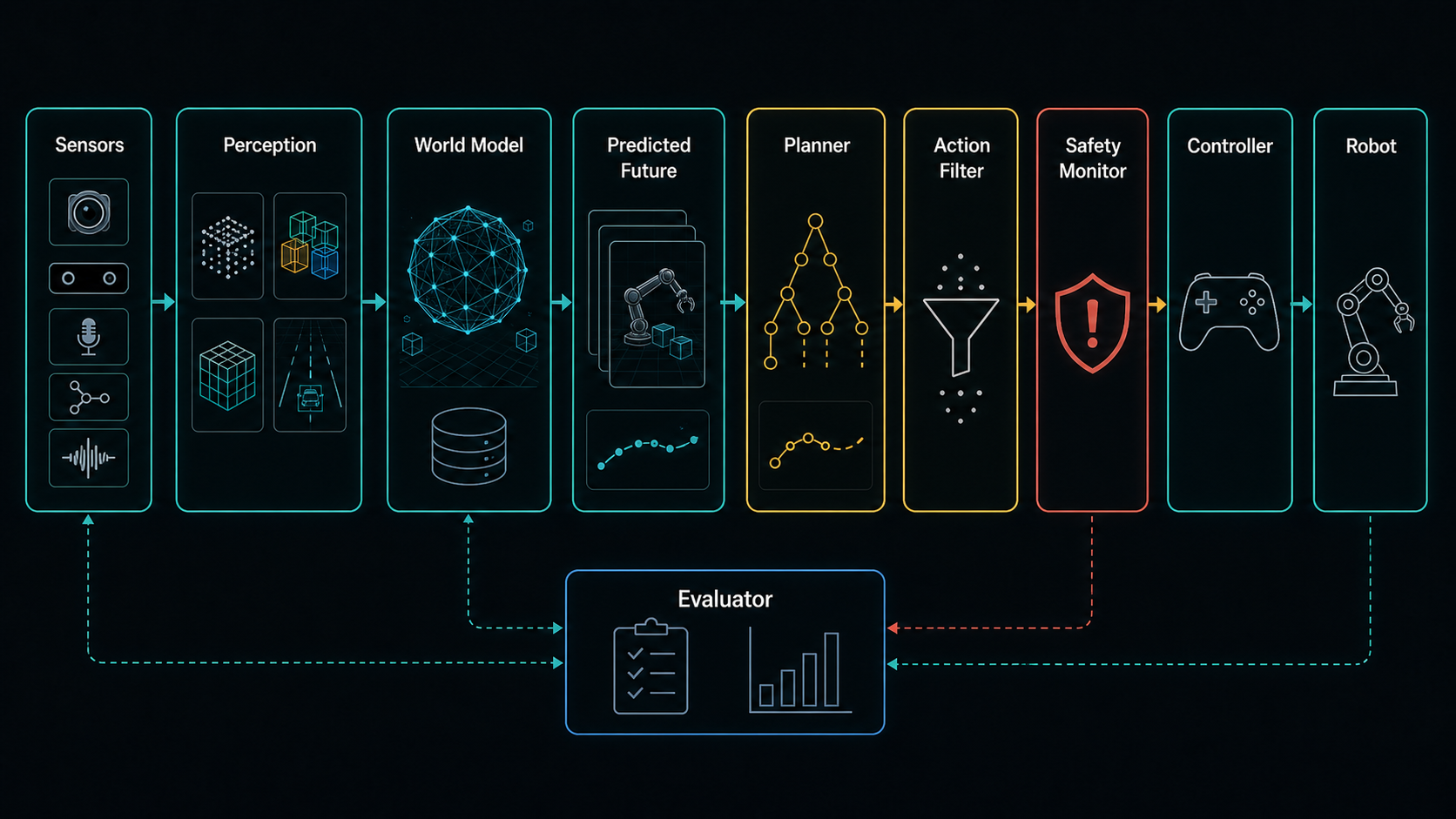
In deployment, a world model usually has one of six jobs.
It can be an evaluator. Given a proposed action or plan, it predicts likely consequences and scores whether they align with the task.
It can be an action filter. If a candidate action leads to a high-risk predicted future, the system rejects it, slows down, or asks for a new plan.
It can be a planner's simulator. The planner searches through short-horizon futures using the learned model.
It can be a training environment. The policy learns from imagined rollouts or future-prediction losses before being tested in the real world.
It can be a representation learner. The system uses world-model objectives to learn features that make the downstream policy better.
It can be a subgoal generator. The model predicts a near-future visual state that a policy should try to realize.
These roles have different latency and reliability requirements. A training-time world model can be slow. A test-time action filter must be fast enough to matter. A planner can tolerate approximation if it replans often. A safety monitor must be conservative around uncertainty.
That is why the deployment question should come early: will the world model run during control, during planning, during training, or during evaluation?
The answer changes the architecture.
It also changes the metrics:
- Training-time model: does the downstream policy need fewer real trials, generalize better, or recover better?
- Planner's model: does it rank short action sequences correctly, even if long rollouts are imperfect?
- Action filter: is uncertainty calibrated enough to reject risky futures without making the robot uselessly timid?
- Evaluator: can it explain failures as collision risk, task mismatch, high uncertainty, predicted slip, or unreachable state?
- Subgoal generator: are the visual targets actually reachable by the lower-level policy?
This is why I would not ask "should we use a world model?" in the abstract. I would ask which of these roles is missing in the robot stack. A lab trying to reduce data collection may need imagined training. A company deploying a manipulation system may need an evaluator and action filter first. A VLA team may need world-model objectives as representation learning rather than test-time rollout.
How to Start Reading the Field
If you are new to world models for embodied AI, I would not start with the largest video generator. Start with the smallest closed loop you can actually run and inspect.
The first exercise is not model training. It is printing one robot episode.
Open one episode from an RLDS-style dataset, Open X-Embodiment-style dataset, or your simulator logs. Print five consecutive timesteps. For each timestep, write down:
- observation keys and shapes;
- action shape, units, and controller convention;
- proprioceptive fields;
- language instruction or task ID;
- reward, success, discount, or termination fields;
- robot name, camera names, and any calibration or embodiment metadata.
Then step through the episode manually:
- Look at frame
and describe the scene. - Read action
in the robot's controller convention. - Compare frame
with what that action should have changed.
This sounds too basic until it fails. If
After that, the practical order should build one concept at a time:
- Inspect episodes before training anything.
- Start in a state-based simulator so the control loop is visible.
- Move to an RGB simulator and add perception.
- Train an action-conditioned predictor.
- Use it as a short-horizon evaluator or planner.
- Compare against a tiny WAM baseline.
The classic transition tuple
Then move from tuple to episode. Inspect RLDS or Open X-Embodiment examples and ask whether the data preserves timestep order, action shape, language instruction, success signal, robot metadata, and episode boundaries. If those fields are vague, a world-model objective will also be vague.
Only after that would I compare methods:
- DreamerV3 teaches how latent imagination trains behavior.
- TD-MPC2 teaches how short-horizon latent planning chooses actions.
- DayDreamer shows what changes on physical robots.
- OpenVLA gives the direct VLA policy baseline.
- Tiny WAM tests whether future prediction actually helps action prediction.
The richer WAM-style tuple
The beginner progression should expose failure modes in this order:
- State-based simulator: learn the control loop without fighting vision. If this fails, the issue is probably dynamics, reward, planning horizon, or implementation.
- RGB simulator: add perception. If performance collapses, the representation is not preserving the state variables the controller needs.
- Action-conditioned predictor: train
or a latent equivalent. Watch one-step error and multi-step drift separately. - Short-horizon evaluator/planner: use the model to rank action candidates, not to generate a long movie. Replan frequently.
- Tiny WAM baseline: compare action-only, future-only, and joint future-plus-action objectives. The question is whether future prediction helps action, not whether the video is prettier.
Expect these failures. Frame/action misalignment will look like random dynamics. Sparse rewards will make value learning brittle. Rollout drift will compound after a few steps. A policy may exploit model errors. A generated future may be visually plausible but impossible for the robot to execute. These are not edge cases; they are the defining tests of whether a model has truly grounded its predictions in the physics of action.
Route 1: DreamerV3 for Latent Model-Based RL
Start with DreamerV3 if you want to understand model-based RL as a training loop.
Do not read it first as "a robot model." Read it as a clean answer to a narrower question: can an agent learn a compact latent model of the environment and train behavior inside imagined trajectories?
The pieces to identify in the code or paper are:
- the replay buffer that stores real environment interaction;
- the encoder that turns observations into latent state;
- the recurrent dynamics model that rolls latent state forward under actions;
- the reward, value, and continuation heads;
- the actor-critic update that happens inside imagined rollouts.
The useful beginner experiment is not to tune a new benchmark. Run a small task, inspect real versus imagined rollouts, and ask where error enters: observation modeling, reward prediction, actor exploitation, imagination horizon, or uncertainty.
Route 2: TD-MPC2 for Continuous-Control Planning
Start with TD-MPC2 if you care about continuous control and planning.
This route is useful because it avoids the trap of equating world models with video generation. TD-MPC2 is about scalable, task-oriented latent dynamics for control. It asks whether a learned model can support model predictive control across many continuous-control tasks.
A reasonable first pass is:
- Clone or read the implementation around a simple state-observation control task.
- Switch the same task to RGB observations.
- Compare what becomes harder when perception enters the loop.
- Inspect the latent dynamics, value, and planning code after you have seen that contrast.
The state-versus-RGB comparison is especially useful. With state observations, the model gets compact variables that are already close to control. With pixels, it must learn perception and dynamics together. That single switch exposes a central robotics theme: world modeling is harder when the state is hidden behind sensors.
Then move from locomotion or DMControl toward a manipulation task such as pick-cube in ManiSkill. Contact, action dimension, sparse rewards, and object pose make prediction errors more consequential. The small experiment I would run is:
- train or evaluate a state-observation model;
- repeat with RGB observations;
- compare rollout error, task success, and sensitivity to planning horizon;
- shorten the planning horizon and replan more often;
- note whether the model is useful for ranking actions even when its long rollout is visually or numerically imperfect.
That last point is the lesson: a control world model does not have to win a video benchmark. It has to choose better actions.
Route 3: DayDreamer for Real-Robot System Design
DayDreamer is the right route if you want to understand what changes when the environment is no longer a simulator.
I would not make it a first-day reproduction target unless you already have the hardware and lab setup. Treat it as a system-design reading exercise. Its value is that it shows how Dreamer-style world-model learning can be organized around real robots: actor process, learner process, replay buffer, resets, asynchronous data collection, and online adaptation.
The key question is not "can I run the xArm command today?" It is how the system keeps learning while the robot interacts with the world. Read for the actor/learner split, replay writes, reset handling, human intervention, proprioceptive versus visual observations, and which parts would be unsafe to run without supervision. This route matters because many world-model papers hide the systems layer. Real robot learning does not.
Route 4: OpenVLA and Open X-Embodiment Before WAM
If your interest is WAMs, first understand the VLA baseline.
OpenVLA is not a world model. It is a vision-language-action policy: observation and language in, action out. That makes it the right contrast. Before asking whether joint future prediction helps, you need to understand the direct policy interface:
Open X-Embodiment and RLDS-style datasets are the data side of that interface. They force you to look at cross-robot data as episodes, timesteps, observations, actions, language instructions, and metadata. This is where WAMs become concrete rather than rhetorical. If the data cannot align observation, language, action, and next observation, the WAM objective has nothing stable to learn.
For a newcomer, the practical path is:
- Inspect RLDS or Open X-Embodiment episodes until the observation, action, language, reward, and metadata fields are concrete.
- Read or run a VLA fine-tuning recipe so the direct policy baseline is clear.
- Build a tiny action-conditioned dynamics model on a simulator task.
- Compare action-only, future-only, and joint future-plus-action objectives.
The tiny WAM project does not need a 7B model. Use ManiSkill, Meta-World, RLBench, or another accessible simulator. Collect random, scripted, successful, and failed trajectories. Train three small baselines:
- Behavior cloning / VLA-style baseline: predict action from observation and instruction.
- World-model baseline: predict next latent state or next observation from observation and action.
- Tiny WAM baseline: predict future state and future action together.
Then ask whether future prediction improves action generalization, recovery from off-distribution states, or evaluation of candidate actions. If not, the joint objective, representation, data mixture, or task choice is not yet helping.
A Minimal Experiment Checklist
A good first project should be small enough that you can inspect every failure.
Use this checklist:
- Pick one simulated manipulation task with a clear success metric.
- Save episodes as ordered transitions, not loose frames.
- Include random actions, scripted successes, scripted failures, and recoveries.
- Train an action-conditioned predictor on
. - Add language only after the basic transition model works.
- Compare state observations against RGB observations.
- Measure one-step error, multi-step rollout drift, and downstream task success separately.
- Add an uncertainty estimate or ensemble before trusting long rollouts.
- Use the model first as an evaluator or short-horizon planner, not as a full robot brain.
This is enough to encounter the real problems: partial observability, compounding error, action alignment, representation choice, and the gap between prediction quality and control quality.
Evaluating WAMs
WAM evaluation has to keep two axes separate.
The first axis is world-model quality. Does the imagined future stay visually and semantically consistent? Does it preserve object identity, contact order, physical plausibility, and action-relevant state? Can another model or inverse dynamics estimator recover the action that would plausibly produce the imagined change?
The second axis is action-policy quality. Does the policy complete tasks, recover from perturbations, generalize to new objects or scenes, and survive real-device deployment?
Neither axis is enough alone. Visual fidelity can reward a beautiful but non-executable future. Task success can hide shallow future prediction if the policy mostly behaves like a strong reactive controller. For WAMs, the useful tests sit between them: perceptual consistency, physical plausibility, action recoverability, task success, latency, and real-robot robustness.
That is why I would not evaluate a WAM only with video metrics or only with success rate. The robotics question is whether the future prediction changes what the robot can safely and reliably do.
Choosing a Direction
The progression above is sequential. The entry points below are parallel — choose the one that matches your background and bottleneck:
- Reinforcement learning: start with DreamerV3, TD-MPC2, replay buffers, latent dynamics, imagined rollouts, value learning, and MPC. Ask how to stop policies from exploiting model errors while keeping sample efficiency.
- Robotics: start with ManiSkill, Meta-World, RLBench, or a small real-robot logging setup. Ask how model error, uncertainty, and task failure correlate under contact.
- Vision or video generation: start with video prediction, latent action, inverse dynamics, and representation learning. Ask whether passive video can produce action variables that transfer to robot control.
- VLA or multimodal modeling: start with OpenVLA, Open X-Embodiment, action tokenization or continuous action heads, and WAM papers. Ask whether future observation prediction improves action prediction on new objects, scenes, or embodiments.
- Systems or industrial robotics: start with evaluator, action filter, planner, training environment, logging, and safety layer. Ask where the model's uncertainty and latency are useful rather than dangerous.
If you specifically care about WAMs, the open problems are concrete:
- Architectural coupling: compare cascaded and joint designs under matched scale, data, and latency.
- Multimodal physical state: move beyond RGB when force, tactile, audio, depth, deformation, or proprioception carries the decisive signal.
- Data mixture design: measure when robot data, simulation, portable human demos, and egocentric video help rather than dilute each other.
- Long-horizon drift: stop prediction and action errors from compounding across subtasks.
- Inference efficiency: make future-aware policies fast enough for closed-loop control.
- Safe deployment: test whether imagined futures remain causally tied to executable actions before trusting them around hardware.
The field is moving because video models, robot foundation models, and model-based RL are finally close enough to talk to each other. But the robotics constraint does not disappear: a robot acts through a body, under latency, with partial observations, uncertain contacts, and consequences that cannot be edited after the fact.
One practical test is simple: does the model help the embodied agent act better on the deployment task, under the relevant latency and safety constraints? If not, it may still be a useful predictor or representation learner, but its value as a robotics world model has not yet been established.
Key Takeaways
- A video generator becomes useful as a robotics world model only when its predictions connect to executable action, planning, evaluation, or safety decisions.
- The core interface is action-conditioned prediction:
. - Latent models, pixel models, JEPA-style predictors, and interactive video models make different tradeoffs between fidelity, efficiency, and control usefulness.
- Robot world models should make uncertainty actionable when rollout drift can create physical risk; the right interface depends on whether the model serves training, planning, filtering, or deployment monitoring.
- World Action Models couple future world prediction and future action prediction, making them a natural bridge between video priors and robot policies.
- Cascaded WAMs are easier to inspect; joint WAMs couple future and action more tightly but are harder to optimize.
- WAMs need two-axis evaluation: future quality and action quality, not video realism alone.
- Deployment decides the architecture: training-time imagination, test-time planning, action filtering, and verification have different latency and reliability requirements.
Citation
Please cite this article as:
Ji, Wenbo. “Embodied AI World Models”. fusheng-ji.github.io (June 2026). https://fusheng-ji.github.io/blog/posts/world-models-for-embodied-ai/
Or use the BibTeX entry:
@article{ji2026worldmodelsforembodiedai,
title = {Embodied AI World Models},
author = {Ji, Wenbo},
journal = {fusheng-ji.github.io},
year = {2026},
month = {June},
url = {https://fusheng-ji.github.io/blog/posts/world-models-for-embodied-ai/}
}References
-
Danijar Hafner et al. Learning Latent Dynamics for Planning from Pixels.
-
Danijar Hafner et al. Mastering Diverse Domains through World Models.
-
Philipp Wu et al. DayDreamer: World Models for Physical Robot Learning.
-
Julian Schrittwieser et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.
-
Yann LeCun. A Path Towards Autonomous Machine Intelligence (JEPA conceptual proposal: OpenReview). See also I-JEPA (arXiv:2301.08243) and V-JEPA (arXiv:2404.08471).
-
Google DeepMind. Genie: Generative Interactive Environments.
-
Google Research. RLDS: An ecosystem to generate, share, and use datasets in reinforcement learning.
-
Open X-Embodiment: Robotic Learning Datasets and RT-X Models.
-
Persistent Robot World Models: Stabilizing Multi-Step Rollouts via Reinforcement Learning.
-
From World Models to World Action Models: A Concise Tutorial for Robotics.
-
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Note: This blog was drafted and polished with the assistance of ChatGPT (GPT-5.4 Thinking), based on my reading notes on embodied AI world models and robot learning papers. Some illustrations were generated with GPT Image 2; official paper figures are attributed in their captions.