On 3D, Video World Models, and the Approaching ImageNet Moment of Perception-Action Learning
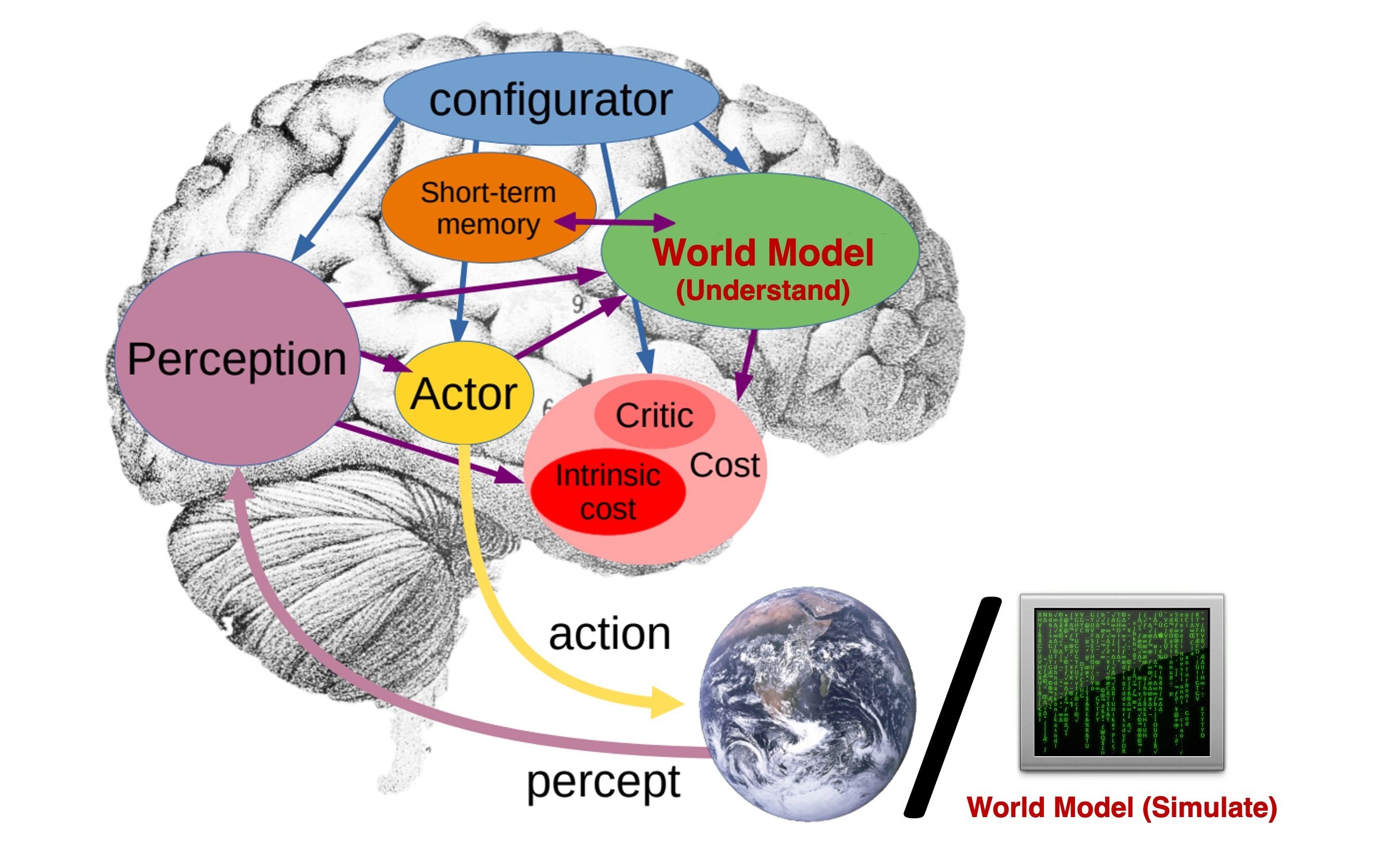
From Vision Tasks to Perception-Action Learning
I recently read Vincent Sitzmann’s blog, The flavor of the bitter lesson for computer vision. What stayed with me was not so much its provocation about the future of computer vision, but a more specific shift in emphasis: from vision as a collection of intermediate tasks to perception as something ultimately judged by its usefulness for action.
For a long time, vision was organized around intermediate problems because direct perception-action learning was simply too hard. Reconstruction, segmentation, tracking, and pose estimation were not arbitrary choices. They were the forms in which the problem became manageable. The question now is what comes after that modular logic stops being enough.
What 3D Was Solving
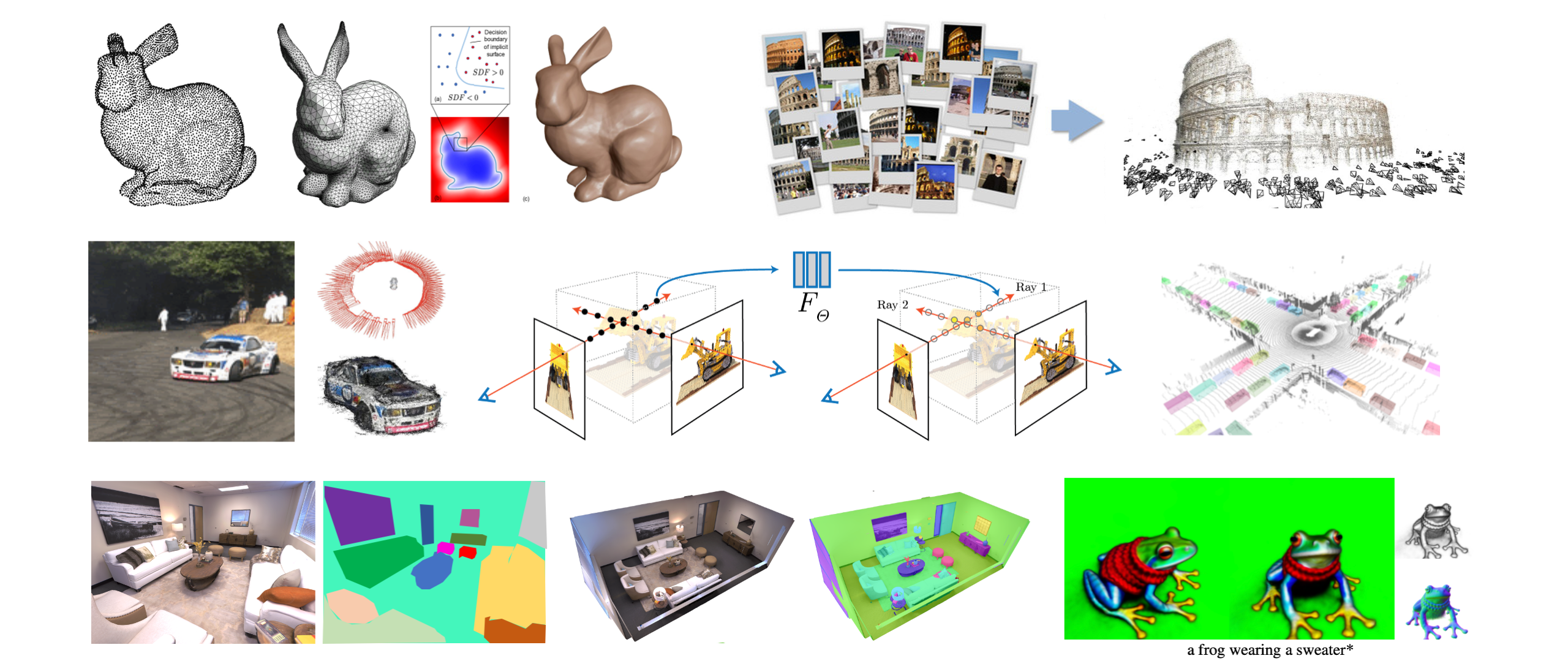
Much of my earlier work lived in 3D reconstruction, scene decomposition, and long-term video tracking. In those settings, explicit structure was the most workable way to make scenes and humans consistent, interpretable, and useful for downstream tasks.
That logic made sense for a long time. But as the goal shifts toward more unified forms of perception and intelligence, its limits become harder to ignore. These components still matter, but together they start to look less like a scalable system and more like a patchwork of useful modules. If 3D is going to stay central, it cannot remain only as a collection of task-specific pieces. That becomes especially clear once perception is judged not only by how well it reconstructs the world, but by how well it supports interaction with it. At that point, 3D needs a more unified, more feed-forward regime of its own.
From 3D to Video World Models
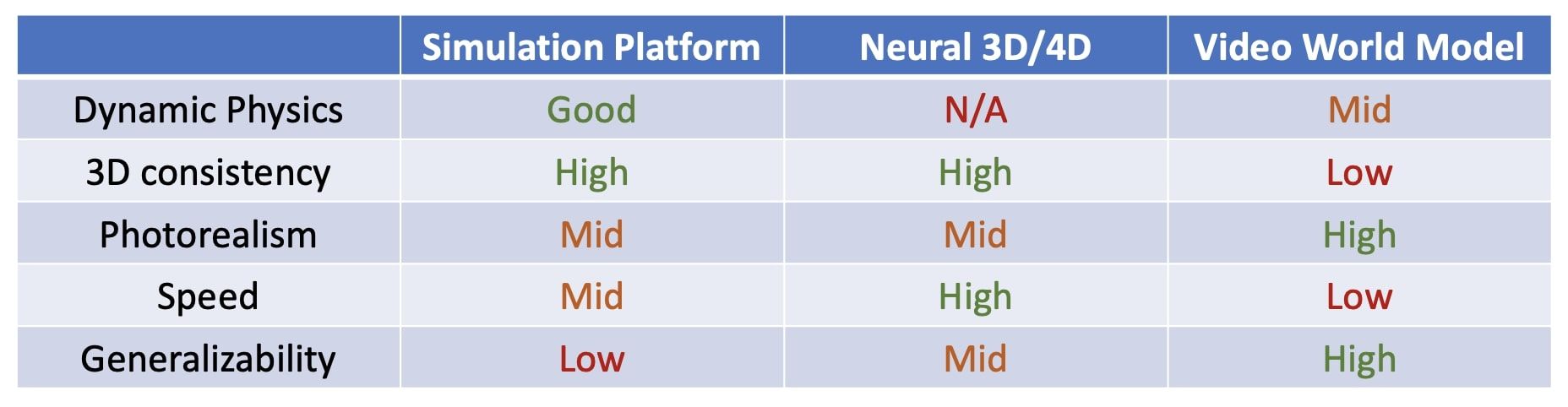
Explicit structure remains useful where pure video generation is weakest: consistency across views and time, geometric coherence, and more physically grounded prediction.
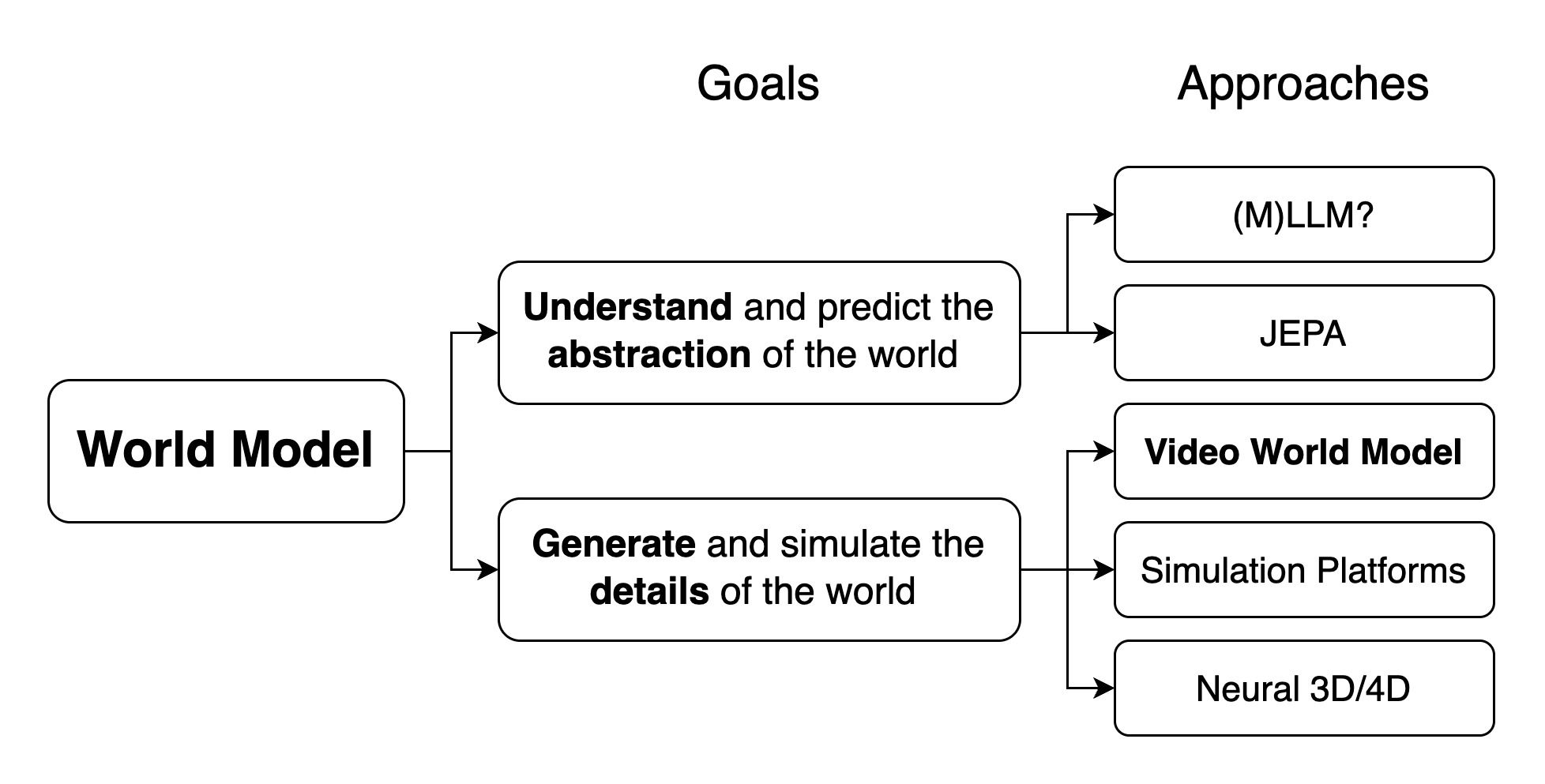
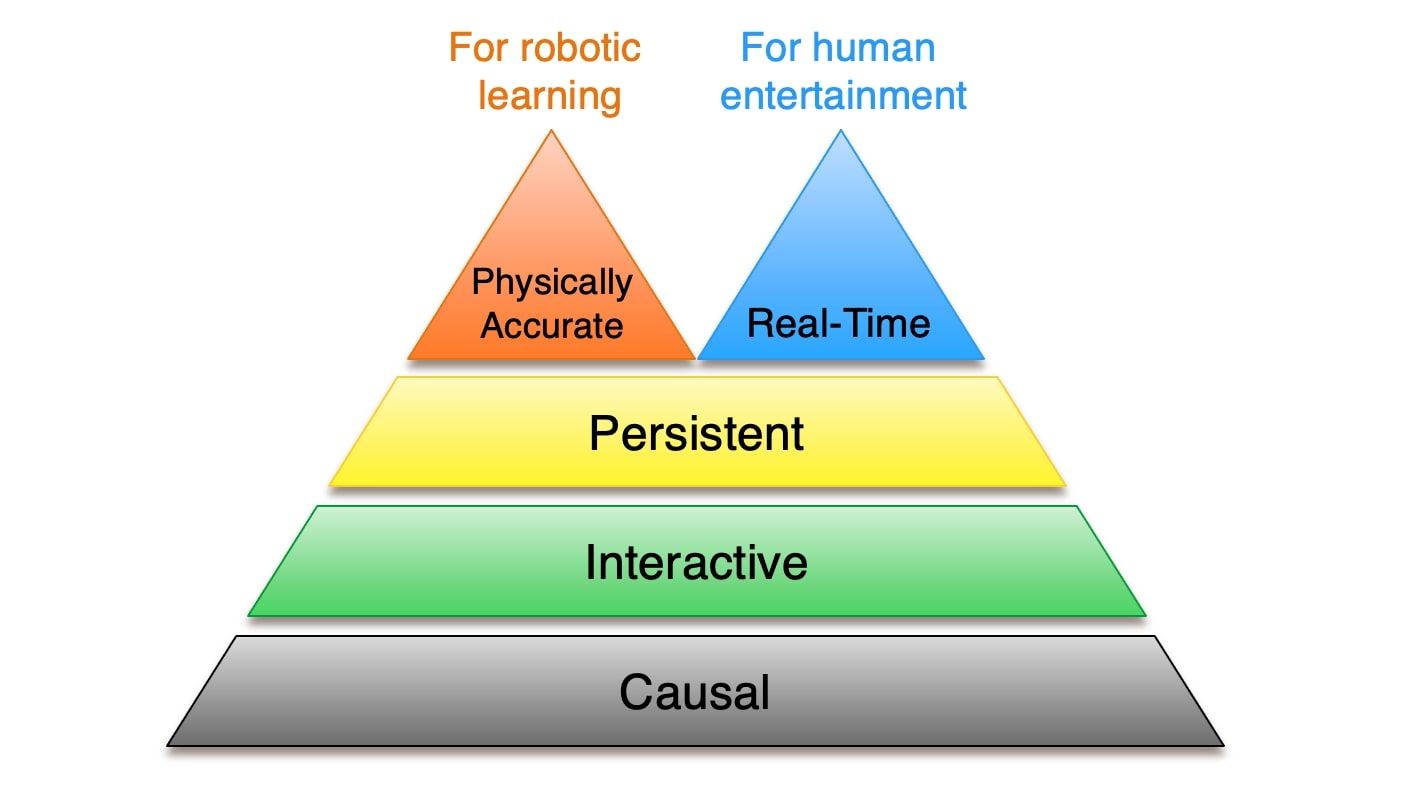
Not all “world models” aim at the same thing. Some organize the world at an abstract semantic level, while others aim to simulate it in enough detail to support interaction and control. This is where video world models start to matter. They do not solve perception-action learning directly, but they may be the most practical bridge we have today: they let us learn temporal structure, dynamics, and behavioral regularities from abundant video before action-conditioned data becomes rich enough to support broader generalization.
That bridge is still incomplete. Interactive controllability depends on video and action being aligned, and obtaining such data at scale remains a central open problem. Even so, 3D and video world models seem less like competing directions than like parts of the same transition: one contributes structure and physical grounding, the other scale in dynamics and behavior.
Beyond Visual Plausibility
The question is no longer whether a model can generate convincing futures, but whether those futures are usable for intervention and control. The gap is not image quality alone, but whether a model can remain coherent over time, support intervention, and stay physically grounded.
A model can generate plausible video and still fall short as a world model. Without causal structure, it cannot tell us what would happen under intervention. Without physical accuracy, even a compelling future may be useless for control. Smooth motion is not enough if contact, inertia, collision, or object consistency fall apart.
Recent work such as VGGRPO points to a more concrete path: using latent-space rewards derived from geometry priors to improve consistency. That does not solve causality by itself, but it does suggest that pushing world models toward more physically grounded behavior may be as much an alignment problem as a modeling one.
Toward the ImageNet Moment of Perception-Action Learning

Figure 6. ImageNet was historically decisive not only because it enabled the 2012 deep learning breakthrough, but because it established large-scale pretraining and fine-tuning as a general recipe for transfer. Source: Xavier Giro-i-Nieto's slides.
If 2D vision had its ImageNet moment, what made it decisive was not scale alone, but the combination of scale, task definition, shared benchmarks, and a common optimization target. It gave the field something stable enough for learning to organize around.
From that perspective, MASt3R and VGGT matter less because they “solve 3D” than because they show that 3D perception can begin to generalize through end-to-end forward training rather than through heavy task-specific pipelines. That shift is important because it moves 3D learning away from explicit optimization and modular reconstruction toward feed-forward models that learn structure directly at scale.
Perception-action learning still seems to be approaching that stage rather than fully reaching it. The central obstacle is not video scale by itself, but the lack of large-scale data that aligns visual change with action, along with the stable tasks, benchmarks, and scale needed for the kind of generalization we ultimately want.
What makes this moment important is not that the answer is already here, but that the shape of the problem is becoming easier to see. And that is exactly what makes it feel like a meaningful time to enter: not to inherit a finished paradigm, but to take part in building one.
References
-
Vincent Sitzmann. The flavor of the bitter lesson for computer vision. discusses the future of computer vision beyond intermediate tasks.
-
Xun Huang. Towards Video World Models. discusses video world models, causality, physical accuracy, and interaction.
-
Jon Barron’s talk discusses 3D vision in the age of video models, and also points to the possible obsolescence of 3D.
-
Saining Xie’s talk discusses world models and related directions.
Note: This blog was polished with the assistance of ChatGPT (GPT-5.4 Thinking).